Ёлкин С.В., Бетин В.Н., Жигарев А., Простаков О.В, Хачукаев Э.М.
Разработка семантического анализа текстов при автореферировании
В статье рассмотрена методика планирования семантического словаря и иерархическая организация его рубрик. Введены понятия семантического пространства и простой семантической меры характеризующей близость понятий как в самом семантическом пространстве так и в его программной реализации – семантическом словаре. Описаны основные лингвистические и логические проблемы не позволяющие создать идеальное семантическое пространство на основе естественного языка.
Применение персональных компьютеров не только ускорило создание и обработку текстовых документов, но и чрезвычайно увеличило их количество и объем. Многие пользователи регулярно сталкиваются с потребностью быстро просматривать большой объем документов и выбирать из них только действительно нужные. Эта задача возникает при работе с текстовыми базами данных, разборе электронной почты и при поиске в Интернет. Во всех указанных случаях полезна возможность автоматически составлять сжатые описания содержания документов – аннотации. Кроме того, часто бывает, что в крупных организациях правила делопроизводства предписывают сопровождать каждый документ кратким рефератом или анотацией.
На сегодняшний день для анализа и реферирования текстов используются преимущественно статистические методы. С помощью подобных методов можно составить только квазиреферат документа. Под автоматическим квазиреферированием (экстрагированием) понимается выделение из исходного текста некоторого количества наиболее информативных предложений. Оценка информативности предложения выполняется автоматически на основе статистических методов. Вес предложения определяется в виде суммы весов слов предложения. В первых работах в качестве веса слова использовалась частота его встречаемости в реферируемом тексте. В дальнейшем помимо частотных критериев стали использовать ряд дополнительных принципов:
1. позиционный, учитывающий местоположение термина в тексте
2. синтаксический (выделение именных групп в предложении)
3. прагматический (повышенный вес получают термины, являющиеся именами собственными)
4. учет не только единичных терминов, но и словосочетаний.
В нашей работе задача автореферирования решалась с помощью семантического анализа. Ранее был разработан семантический словарь, в основе которого лежала концепция «Семантического пространства» [1, 2]. Согласно этой концепции смысл понятия интерпретируется как положение его в классификаторе (семантическом пространстве), имеющего шестнадцать главных рубрик (семантических осей). Каждая рубрика в свою очередь делится (в глубину) на более мелкие рубрики (семантические координаты), уточняющие ее смысл и так далее. Двум разным семантическим интерпретациям одной и той же инфинитивной формы (слова) соответствуют разные наборы рубрик (координат) по классификатору. В данный момент в словаре имеется ~70 тыс. понятий разложенных по трем тысячам рубрик (координат). Ранее семантический словарь уже применялся для решения задачи машинного перевода и прекрасно себя зарекомендовал при снятии проблемы омонимии. В частности созданный для этого семантический анализ позволял определять семантическую меру вхождения слова в совокупный набор рубрик (координатное представление) для каждого конкретного предложения. Конкурирующие омонимы имеют различную меру вхождения для конкретного предложения, что позволяет выбрать тот из них, который дает больший вклад в общую семантическую меру.
Ранее в работе [3] сообщалось о создании семантического словаря и кратко описывалась его структура. Здесь мы рассмотрим его организацию с другой точки зрения. Принципиально возможность представления любого слова через набор других слов, обычно называемых «элементарными семами» не вызывает у специалистов сомнения. Однако при реализации данной идеи возникает ряд проблем. В частности, не ясно, какие слова могут служить «элементарными семами», а какие не могут. Интуитивно понятно, что в качестве элементарных лучше брать неопределяемые понятия, однако набор таких понятий для всего естественного языка в целом до сих пор не определён, да и сама возможность такого определения вызывает сильные сомнения. Не существует, сколько-нибудь единого мнения о количестве «элементарных сем», через которые могут быть выражены все остальные слова. В каждой конкретной предметной области науки или техники набор неопределяемых понятий примерно, а иногда и точно (как например, в некоторых разделах математики) известен, но все меняется при переходе к общей лексике естественного языка. Предполагаемое количество исходных понятий у разных авторов колеблется от 30 до 2000 [4]. Таким образом, задача выделения «элементарных сем» перерастает лингвистические рамки и становится методологической и философской.
Ранее при попытке конструирования универсального языка В.В. Куликов использовал категории классической немецкой философии. В созданном им языке Диал понятия следующих уровней синтезировались из понятий предыдущих уровней. Каждое понятие имело противоположное объединяясь с которым в синтезе оно превращалось в новое понятие, при этом неявно наследуя смыслы понятий-родителей (см. рис.1), и затем вновь должно было приобрести противоположное понятие. Такой подход позволил построить строгое математическое описание Диала на языке частичных алгебр [2].
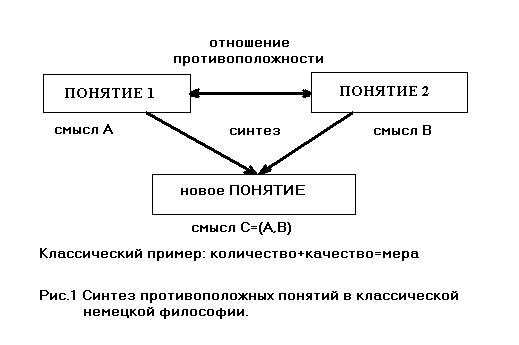
В нашей работе мы воспользовались результатами, полученными в вышеуказанных работах.
Исходные предположения:
1. Не существует абсолютно элементарных, неопределяемых понятий. Любое понятие, претендующее на роль элементарной семы элементарно лишь относительно.
2. Каждая элементарная сема должна обладать возможно меньшим количеством в идеале одним противоположным понятием.
3. Понятие, наследующее смысл «понятий-родителей» более конкретно по отношению к ним.
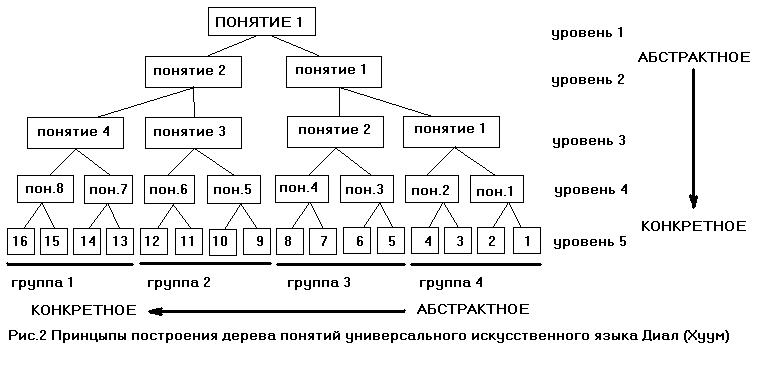
4. Наследование сем может быть представлено бинарным деревом см. рис.2.
Рассмотрим более подробно семантическое наследование. В корне дерева должно стоять наиболее абстрактное понятие или пара противоположных понятий. На каждом уровне бинарного графа каждая вершина соответствует некоторому понятию, а вновь синтезированные понятия находятся вместе с исходными понятиями предыдущего уровня. И так далее. В результате на каждом уровне имеются все понятия содержащиеся во всех предыдущих уровнях. В последнем уровне находятся понятия всего дерева. Такая структура позволяет ввести понятие «семантического пространства». Для этого последний уровень разделяется на группы понятий соответствующих разным уровням. При этом имеется некоторая свобода действий. Результатом разделения будет набор групп понятий. В каждой группе понятия стоят не случайным образом, а упорядочены от абстрактного к конкретному.
В семантическом пространстве каждой группе поставим в соответствие координатную ось (семантическую), а каждому понятию собственно координату. Количество осей координатной системы в таком семантическом пространстве будет зависеть от способа разделения на группы понятий (см. рис.3).
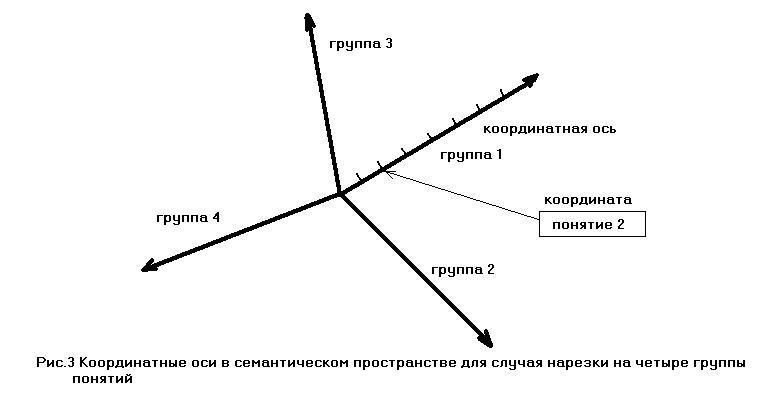
Будем называть такой способ построения семантического пространства линеаризацией графа. На данном этапе для приложений нас интересовала лишь метрика пространства, так как для семантического анализа важна близость понятий. Ортогональность, неравенство треугольника и другие свойства в данной работе не рассматриваются.
Это идеальное представление, реализованное в языке Диал. В действительности же все гораздо сложнее. В естественном языке имеется множество различных типов отклонения от идеальной конструкции:
1. не для каждого слова можно найти его точную противоположность (или антоним);
2. отсутствует точный или строгий критерий противоположности;
3. для большинства слов являющихся сложными понятиями, имеется много слов претендующих считаться противоположными и необходимо выбирать одно из них;
4. не для каждой пары противоположных понятий можно найти понятие объединяющее их смыслы;
5. смыслы многих слов образуются в языке от объединения смыслов слов не являющихся близкими противоположностями;
6. для дерева в целом, не все ветви прорастают на одну и туже глубину, что не позволяет на последнем уровне собрать все понятия всего дерева в целом;
7. картину языкового хаоса дополняют синонимия, омонимия и другие общие и специфические языковые явления.
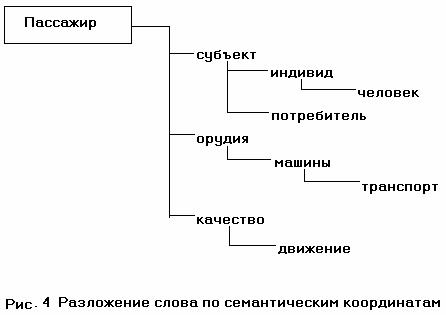
В следствии этого было принято решение сделать срез дерева понятий на таком уровне, на котором было бы наименьшее количество проблем. В результате получилось 16 групп понятий, которые интерпретируются как соответствующие семантические (они же координатные) оси. (Другой очевидной интерпретацией является представление семантических осей как совокупности рубрик.) Важным моментом оказалось то, что на месте отдельного понятия-координаты располагается ветка дерева, причем каждый следующий уровень ветки уточняет значение. Каждое слово с помощью такой «системы координат» можно представить как граф в котором сохраняется родовое наследование. Например, как на рис.4.
Для решения задачи семантического реферирования необходимо преодолеть проблему полисемии – многозначности слова, и её частного случая – омонимии. Метод разложения слова по семантическим координатам позволил создать семантический анализатор описанный в работе [ 3] и применённый в машинном переводчике «Кросслейтор 1.0» НПК «Диалинг» [5]. Ниже излагается лишь основная идея.
Рассмотрим работу анализатора на конкретном примере.
Предложение: «Программист купил новую мышь» содержат явную омонимию в слове «мышь». В семантическом словаре слово «мышь» имеет два разложения (см.рис.5). Одно из них содержит элементарную сему «грызун», а другое сему «компьютер».
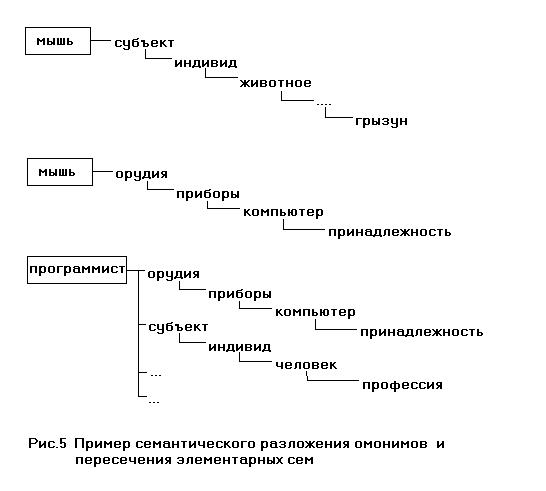
Слово «программист» также содержит сему «компьютер» и очевидно, что это можно использовать для выбора между двумя омонимами слова «мышь». Конечно, выбор можно сделать, сличив между собой семы, но когда предложение имеет много слов и количество омонимов также велико, или в задаче машинного перевода, когда одно слово может иметь несколько десятков значений, алгоритм перекрестного сличения сем «в лоб» уже не годиться. Что бы решить эту проблему мы ввели понятие «семантической меры».
Определение 1: под семантической мерой ? совместного семантического разложения группы понятий будем понимать сумму произведений частоты встречаемости V-1 семы на уровень глубины L семы в дереве ?=?L*(V-1). (См. рис.6)
Частоту встречаемости будем считать равной V-1 если в общем семантическом дереве группы понятий некоторая сема встречается V раз. То есть частота встречаемости всегда на единицу меньше. Это необходимо, что бы учитывать только пересекающиеся по смыслу понятия.
Определение 2: группу понятий будем называть семантически связной, если их семантическая мера больше нуля.
Определение 3: группу понятий будем называть полностью семантически связной, если их семантическая мера больше нуля и среди них нет такого понятия удаление которого не меняло бы величину семантической меры.
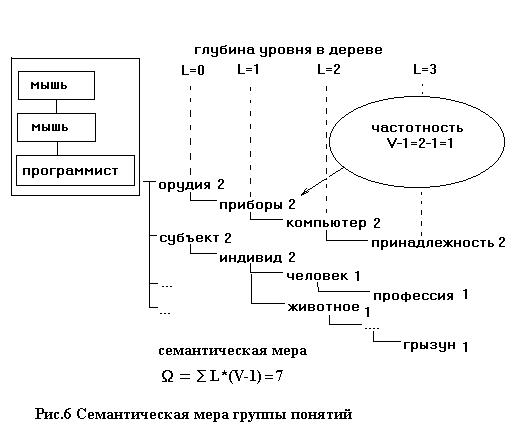
Если оба омонима дают вклад в семантическую меру, то нужно выбрать тот из них который дает больший вклад. В нашем примере «мышь (как принадлежность)» дает вклад в меру равный 6, а «мышь (как грызун)» дает вклад равный 1. Меру можно отнормировать на число слов, вершин, уровней, суммарную частоту встречаемости или на её максимальное значение в данной группе понятий. Всё зависит от решаемой задачи. И это не единственный способ определения семантической меры и проведения семантического анализа, например, в работе [3] мера имела более сложный вид, а для анализа использовался метод «ветвей и границ».
Теперь можно приступить собственно к изложению идей автореферирования. Имея семантическое разложение каждого слова и умея вычислять связность группы слов, несложно распространить их на предложение в целом или любую другую единицу текста. Для автореферирования необходимо определять семантическую близость между предложениями текста. Эта задача была решена методом, названным нами «метод семантической матрицы».
Для каждого предложения в тексте определяется совокупная семантическая мера. Затем вычисляется семантическая связность всех пар предложений в тексте, как разность совокупной меры двух предложений и меры каждого из них:
Из получившегося набора семантических связностей формируется семантическая матрица. Матрица симметрична, на главной диагонали стоят нули, так как связность предложения с самим собой в данный момент нас не интересует. Элементы матрицы ранжируются по величине. Пара предложений имеющих максимальную семантическую связность (максимальный элемент матрицы) порождают первую группу предложений реферата. Следующая пара предложений по ранжиру проверяется на семантическую связность с уже существующими группами и добавляется в одну из них либо образует новую группу. В результате семантического реферирования получается одна или несколько групп предложений объединённых общей семантической связностью.
В целом процесс реферирования состоит из следующих этапов.
1. Графематический анализ (определение границ предложения с возможностью настройки).
2. Морфологический анализ.
3. Устранение омонимии слов в предложении.
4. Построение семантической матрицы.
5. Выделение семантически связных групп предложений.
Данный тип реферирования позволяет реализовать следующие пользовательские функции.
1. Заданную степень сжатия (определяет количество предложений, оставляемых в реферате с максимальной семантической мерой и связностью)
Степень конкретизации (порог семантической связности по величине ?i , задаваемый пользователем)
2. Количество групп рефератов одного текста (пороговое значение Mij для объединения в один реферат близких по смыслу групп предложений)
Эти функции являются нелинейными и сильно связаны с характером текста.
Замечание. Обычно различают семы – предельные значения плана содержания слова и семемы – непредельные значения. В данной работе мы не использовали их различие, так как приняли за основание относительность элементарной семы.
К недостаткам разработанных семантического словаря и анализатора можно отнести недостаточно тонкое различение смыслов. Например, при машинном переводе невозможно семантически установить разницу между близкими по смыслу глаголами, которая тем не менее оказывает существенное влияние на качество перевода. При автореферировании количество семантически связанных предложений не превышает 70%, поэтому эффективное смысловое сжатие текста начинается лишь с коэффициента 1:2. При реферировании узкоспециальных текстов качество реферирования снижается, так как по каждой теме необходимо вводить в словарные базы соответствующую лексику.
Тем не менее созданная технология представляет хорошую стартовую площадку для развертывания целого класса работ на её основе: семантического поиска и рубрицирования, семантико-графического представления текстов, семантических диалоговых систем.
Литература
1. Куликов В.В., Гаврилов Д.А., Елкин С.В. Универсальный искусственный язык- “НOOM-Диал”, М.Гэлэкси нэйшн, 1994
2. Елкин С.В.. К вопросу об информационной физике. Часть 1., -М.: ПАИМС, 1997.
3. Бетин В.Н. Елкин С.В. Хачукаев Э.М. Принципы построения семантического словаря для решения задачи устранения омонимии. Вестник ВИНИТИ (в печати).
4. Мельчук И.А. Опыт теории лингвистических моделей «Смысл – Текст». – М.: Школа «Языки русской культуры», 1999.- с.58.
5. Э.С. Клышинский, А.С. Андреев, С.В. Ёлкин, Метод машинного перевода текстов // Сб. трудов 3-го научно-практического семинара "Новые информационные технологии". М.: МГИЭМ, 2000, сс. 58-63.