Аннотация
Построена модель анимата (искусственного организма), осуществляющего поиск экстремума функции
двух переменных. Анимат имеет систему управления, которая содержит автомат (подобный автоматам
с линейной тактикой М.Л. Цетлина), этот автомат обеспечивает определенную инерционность в
принятии решения аниматом. Проведенное моделирование показало, что при достаточно естественном
выборе параметров модели поведение анимата качественно соответствует поисковому поведению живых
организмов.
Abstract
The model of an animat
(artificial organism) searching for an extreme of a function of two variables
has been created. The animat has a control system that contains an automaton
(that is similar to M.L. Tsetlin’s automatons with linear tactics), this
automaton ensures certain inertia at animat’s decision making. The simulation
has shown that at the natural choice of model’s parameters the behavior of the
animat corresponds qualitatively to the searching behavior of living organisms.
1. Введение
С начала 90-х годов активно развивается
направление исследований «Адаптивное поведение» [1-3]. Это направление
заключается в построении и изучении искусственных «организмов» (компьютерных
программ или роботов), которые могут приспосабливаться к окружающей среде.
Такие «организмы» получили название «аниматы» (от англ. animat = animal +
robot). При моделировании адаптивного поведения исследователи стремятся
использовать те принципы и конструкции, которые могут присутствовать как у
живых организмов, так и искусственных аниматов.
Аниматы могут имитировать
поисковое поведение животных и используемые при этом принципы могут применяться
для поиска экстремумов функций [3-6]. Рассмотрим некоторые подходы к
моделированию поискового поведения, кратко характеризуя некоторые биологические
примеры и соответствующие модели.
В работе [5] исследовались
механизмы ориентации самцов тутового шелкопряда в струе феромона самки. Самец
воспринимает запах с помощью рецепторов, расположенных на симметричных
антеннах. И, казалось бы, что самцу нужно двигаться прямо по градиенту
феромона. Но как показало компьютерное моделирование, такая стратегия не
соответствует реальному поведению бабочек. Ориентация самцов включает в себя не
только повороты в сторону наибольшего раздражения, но и спонтанные, независимые
от раздражения зигзаги при движении в струе запаха, а также петли, описываемые
самцами, вышедшими за пределы струи. Можно сказать, что поиск источника запаха
включает в себя, две чередующиеся «инерционные» тактики: а) устойчивое движение
в выбранном направлении, 2) устойчивое повторение поворотов, приводящее к
выбору нового направления движения.
Интуитивно понятно,
что чередование этих тактик действительно может быть выгодно. Движение
насекомых против ветра или по градиенту в ответ на запах феромона или пищи, в
принципе, позволяет найти источник запаха. Однако запах в турбулентном потоке
воздуха распределен не равномерно, а отдельными «облаками». Если насекомое
перестает воспринимать запах, то все же некоторое время продолжает движение
против ветра, как бы предполагая, что вслед за первым облаком появится и
второе. Если новое облако не встречается, то можно предположить, что насекомое
отклонилось от правильного направления, и оно меняет тактику: движется
зигзагами поперек ветра. Это помогает вновь найти струю запаха, если насекомое
действительно потеряло направление. Разумеется, насекомому не известно заранее,
в каком случае оно просто вышло из облака, но движется в правильном
направлении, а в каком случае направление потеряно. Однако чередование тактик
позволяет в большинстве случаев достигать цели.
Такое чередование тактик
достаточно общее. Например, в работе [6] исследовалось поведение нематод (круглых червей) Caenorhabditis elegans, которое
продемонстрировало, что в процессе хемотаксиса нематоды так же, как и бабочки
чередуют две тактики: а) движение в определенном направлении и б) повторение
поворотов, приводящее к выбору нового направления движения (пируэты).
Модель чередования указанных двух тактик поиска
(устойчивого движения в избранном направлении и выбора/поиска нового
направления), была предложена и исследована в работе [7]. Эта модель предлагает
систему управления, в которой переключение между тенденциями движения анимата
прямо и поворотами направо и налево обеспечивается с помощью нелинейного
стохастического процесса (а именно, с помощью логистического отображения). Эта
модель качественно соответствует поведению с чередованием указанных двух тактик,
однако, используемое в ней логистическое отображение не позволяет в явном виде
представить механизм переключения между двумя поисковыми тактиками. В связи с
этим в настоящей работе предлагается модель поискового поведения, которая явно
включает в себя такой механизм переключения: в каждый момент времени анимат
выбирает одно из двух решений: А) двигаться в выбранном направлении, либо Б)
изменить направление движения случайным образом. Переход от одного типа решения
к другому моделируется с помощью определенного автомата (аналогичного автомату
с линейной тактикой М.Л. Цетлина [8]). Роль автомата в нашей модели –
обеспечение инерционности переключения между указанными типами решений,
характерной для поискового поведения животных и, по-видимому, существенной для
адаптивного поиска. Для определенности мы считаем, что анимат ищет максимум
функции двух переменных, например, максимум распределения пищи.
2.Описание модели анимата
2.1. Основные предположения
модели
Основные предположения модели состоят в
следующем:
1. Рассматривается
анимат, который может двигаться в двумерном пространстве x,y.
2. Имеется определенное
пространственное стационарное распределение f(x,y).
Задача анимата – поиск максимума функции f(x,y).
3. Анимат функционирует
в дискретном времени.
4. Анимат может
оценивать изменение текущего значения функции f(x,y) по сравнению с предыдущим тактом времени Δf(t)
= f(t) - f(t-1).
5. Каждый такт времени
анимат совершает движение, при этом его координаты x, y изменяются на
величины Δx(t) , Δy(t) соответственно.
6. Анимат имеет свою
систему управления, на вход которой поступают величины Δf(t)
, Δx(t), Δy(t).
7. Система управления
определяет смещение анимата в следующий такт времени Δx(t+1), Δy(t+1).
8. Система управления
содержит автомат (подобный автоматам с линейной тактикой М.Л. Цетлина [8]),
этот автомат обеспечивает определенную инерционность в принятии решения
аниматом.
9. Автомат имеет 2n состояний, номера состояний равны j = -n,
…-2, -1, 1,2,…, n. Если j положительно, то анимат принимает
решение А (двигаться в выбранном направлении), если j отрицательно, то анимат принимает решение Б (поворачиваться
случайным образом). Подробно автомат описан в разделе 2.2 (рис.2).
10.
Решение А. При движении в выбранном направлении анимат
смещается на величину R0 :
Δx(t+1) = R0 cosφ0 , Δy(t+1) = R0 sinφ0 , (1а)
где угол φ0
характеризует сохраняющееся направление движения анимата, φ0 = arctg [Δy(t) / Δx(t)]
.
Решение Б. При случайном повороте
анимат смещается также смещается на некоторую величину r0 , а направление его движения случайно варьируется:
Δx(t+1) = r0 cosφ, Δy(t+1) = r0 sinφ , (1б)
где φ
= φ0 + w, φ0
– угол, характеризующий направление движения в текущий такт времени t,
w нормально распределено
(среднее значение w равно нулю,
среднее квадратическое равно w0),
φ – угол, характеризующий
направление движения в следующий такт времени t+1. Параметр w0
по порядку величины выбирается равным π/4.
11. Алгоритм воздействия на автомат в нашем
случае состоит в следующем: если Δf(t) > 0 , то автомат поощряется, если
Δf(t) < 0, то автомат
наказывается. При поощрении/наказании состояния автомата меняются, как изложено
ниже.
2.2.
Схема автомата
Автоматы, предложенные и исследованные М.Л. Цетлиным и его
последователями [8-10], обладают инерционностью и могут использоваться для
моделирования инерционности переключений между разными режимами поведения.
Например, автомат с линейной тактикой (рис. 1) может находиться в одном режиме
поведения при j > 0, либо
во втором режиме – при j < 0; j – номер состояния автомата.
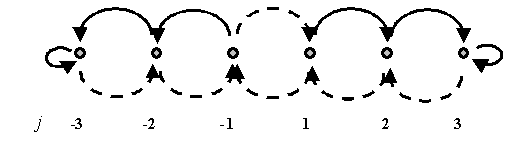
Рис. 1. Схема обычного автомата с линейной
тактикой. j – номер состояния автомата. Сплошными стрелками
показаны изменения состояний автомата при поощрении (выигрыше), штриховыми –
при наказании (проигрыше). Для определенности представлен случай автомата с 6-ю
состояниями.
Для автомата, представленного на рис.1, предполагается, что при
положительных состояниях автомат совершает первое действие (или находится в
первом режиме), а при отрицательных состояниях – совершает второе действие. Если
автомат поощряется (получает выигрыш), то номер состояния увеличивается по
абсолютной величине, если автомат наказывается, то номер состояния уменьшается
по абсолютной величине и, в конце концов, может сменить знак. При такой схеме
автомат «стремится» сохранить тот режим, который приводит к поощрениям. Причем
автомат имеет определенную инерционность – при наказуемых действиях он не сразу
меняет режим, а меняет его только тогда, когда наказывается многократно.
Мы могли бы использовать данную схему
автомата для моделирования инерционности переключения между двумя тактиками
поведения анимата: А) движения в выбранном направлении, и Б) случайного поиска
подходящего направления. Однако при этом возникает одна сложность, связанная с
тем, что в нашем случае один из режимов – случайный поиск: а именно, если
автомат выбрал случайный поиск и получил при этом поощрение (т.е. нашел
правильное направление движения), то он будет дальше развивать случайный поиск,
что уведет его от найденного решения.
Поэтому мы
несколько модифицировали схему автомата, чтобы обеспечить его адаптивную работу
с учетом режима случайного поиска. Схема автомата в нашем случае имеет вид,
представленный на рис. 2.
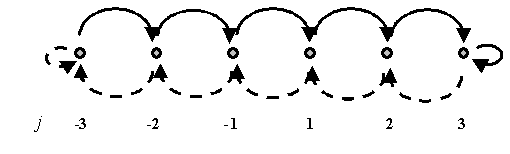
Рис. 2. Схема модифицированного автомата. Для
определенности показан случай n = 3.
Переходы между состояниями при поощрении/наказании показаны
сплошными/штриховыми стрелками.
Правая область данного
автомата совпадает с таковой в обычном автомате (рис. 1). А в левой области
переходы «поменяли знак»: на рис. 1 при поощрении/наказании переходы происходят
влево/вправо, а для нашего модифицированного автомата – вправо/влево,
соответственно.
Рассмотрим качественно
поведение анимата, в систему управления которого входит предложенный здесь
автомат (показанный на рис.2). Если выбранное направление движения анимата в
течение некоторого времени правильное, т.е.
Δf(t) > 0 и автомат поощряется, то автомат переходит из 1-го
состояния во 2-ое и так далее, до n-го.
После того, как движение в данном направлении приводит к неудаче, Δf(t)
< 0, то автомат совершает обратный процесс: из n-го состояния в (n-1)-ое
и т.д., причем все это время продолжается движение в ранее выбранном
направлении. Это нужно, чтобы небольшие локальные ухудшения не могли сразу же
сбить анимата с «верного пути». После достижения (-1)-го состояния анимат
совершает случайные повороты. Если поворот неудачный, то номер состояния
продолжает уменьшаться. В итоге, анимат сделает несколько поворотов, прежде чем
найдет нужное направление в (-1)-ом состоянии и вновь перейдет к движению в
новом выбранном направлении.
Итак, если анимат движется в
«хорошем» направлении (величина f
увеличивается), то он движется в таком направлении, пока не «почувствует», что
оно неправильно, причем на случайные уменьшения f он не обращает внимания. Это движение соответствует правой
стороне состояний автомата. И прекращает двигаться в этом направлении только
тогда, когда «статистически достоверно ощутит», что направление надо менять.
Это соответствует переходу от правой стороны состояний автомата к левой. На
левой стороне он ведет случайный поиск нового «хорошего» направления. Причем
делает несколько попыток поиска, и, в конце концов, находит новое «хорошее»
направление. В результате поиска он снова переходит на правую сторону состояний
автомата.
Отметим, что на рис. 2
представлен детерминированный автомат. Мы также рассматривали и аналогичный
вероятностный автомат. Для вероятностного автомата, характеризуемого
вероятностью р, переходы
осуществляются с вероятностью р так же, как для детерминированного
автомата, и противоположные переходы с вероятностью 1- р (1 ≥ p ≥ 0.5). При р = 1 автомат
детерминированный, при р = 0.5 переходы между соседними состояниями
автомата происходят полностью стохастично.
Для детального анализа
поискового поведения анимата в рамках изложенной модели была создана
компьютерная программа на языке Java и была выполнена серия
компьютерных экспериментов.
3. Результаты моделирования
3.1.
Схема моделирования
При моделировании
оптимизируемая функция f(x,y)
задавалась в единичном квадрате 0 < x,
y <1. При этом в некотором
количестве опорных точек значения функции задавались случайно (в интервале 0
< f <1), а для произвольных
значений x и y значения функции f(x,y)
определялись путем непрерывной интерполяции по опорным точкам. Линии уровня
типичной функции (имеющей несколько локальных максимумов) представлены на рис.
3.
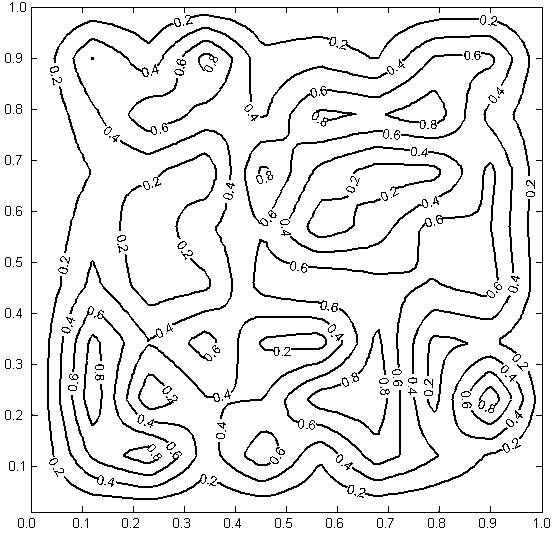
Рис. 3. Линии уровня функции f(x,y).
Модель содержит несколько
параметров: R0 – величина смещения анимата за один такт времени при
движении в выбранном направлении, r0 и w0 – величина смещения и среднее квадратическое значение
угла при случайном повороте, n –
глубина памяти автомата, p – вероятность, характеризующая переходы состояний автомата.
При расчетах из разумных
соображений был выбран опорный вариант, для которого параметры составляли: R0 = 0.001, r0
= 0.001, w0 = π/4
, n = 3, p =1.
Расчет проводился как для опорного варианта, так и для наборов
параметров, в которых один или два заданных параметра отличались от значений
опорного варианта. Тем самым проверялось влияние того или иного параметра на
характер поискового поведения анимата.
При расчете определялись траектории движения анимата и зависимости
оптимизируемой функции от времени. Исходно анимат помещался в центр единичного
квадрата x(t =0) = y(t =0) = 0.5.
При исследовании модели
также производится расчет среднеквадратичных флюктуаций перемещения анимата,
которые позволяют судить о броуновском или неброуновском характере движения
анимата. Использовалась методика, изложенная в [11]. При этом расчете все время
эксперимента делилось на достаточно длительные отрезки («эпохи») длительностью
100 тактов и рассчитывалась функция u(T), значение которой равно числу тех тактов в
течение данной «эпохи», для которых анимат находился в состоянии Б, т.е. искал
новое направление движения. При этом T – номер «эпохи».
Очевидно, что значение u(T) может принимать значения от 0 до 100. Затем
определялось суммарное смещение y(T) = Σi u(i), где i = 1,…,T. Среднеквадратичная флюктуация перемещения равна
F(T) = {<(Dy(T))2>
– <Dy(T)>2}1/2, (2)
где Dy(T) = y(T + T0)
– y(T0). Усреднение в (2) проводится по всем возможным T0. В результате получались
зависимости F(T) ~ Ta. При a = 0.5, имеет место
броуновский характер движения, а при a ¹ 0.5 – неброуновский.
3.2.
Расчет для опорного варианта
Расчет опорного варианта (R0 = 0.001, r0
= 0.001, w0 = π/4
, n = 3, p =1) был проведен для несколько реализаций, отличающихся
генераторами случайных чисел, определяющих действия анимата. Результаты
моделирования для опорного варианта (для двух разных реализаций) приведены на
рис. 4-8.

Рис. 4. Траектория анимата в координатах x, y.
Опорный вариант. Первый случай.
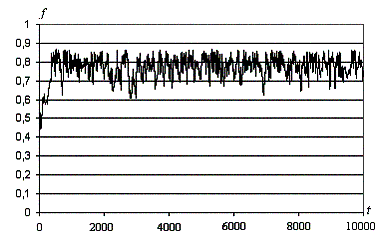
Рис. 5. Изменение значения оптимизируемой
функции со временем f(t). Опорный вариант. Первый случай.

Рис. 6. Пример зависимости lg F (lg T). Опорный вариант.
Первый случай
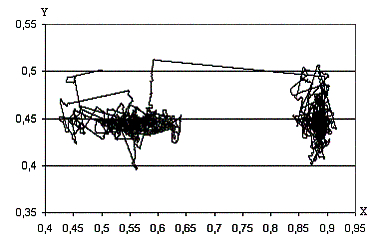
Рис. 7. Траектория анимата в координатах x,y.
Опорный вариант, второй случай.
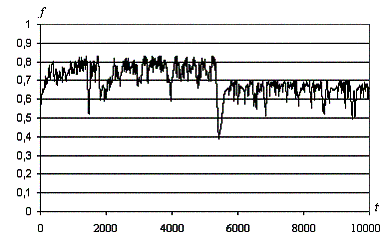
Рис. 8. Изменение значения оптимизируемой
функции со временем f(t). Опорный вариант, второй случай.
Приведенные результаты показывают, что:
- В целом движение анимата качественно
соответствует поисковому поведению животных, есть чередование двух тактик –
движения в выбранном направлении и случайных резких поворотов.
- Движение анимата распадается на
сравнительно короткие перемещения в определенном направлении и долгие блуждания
в окрестностях локальных максимумов оптимизируемой функции f(x,y).
- Анимат способен перейти из окрестности одного локального экстремума в
окрестность другого даже после долгого блуждания (рис.7, 8).
- Движение анимата имеет неброуновский характер. Параметр α равен 1.314 ±
0.013 (рис. 6).
3.3. Расчеты для разных
значений параметров
Мы провели несколько серий
расчетов, варьируя параметры модели. Общие выводы для этих расчетов заключаются
в следующем: мы довольно удачно «угадали» разумные значения параметров опорного
варианта, сильная вариация некоторых параметров резко ухудшала качество поиска
экстремумов функции f(x,y).
Тем не менее, было и улучшение качества поиска, например, для вероятностного
автомата и при увеличении шага движения R0
при решении А. Для всех проведенных расчетов имеет место неброуновский характер
движения. Показатель α в
зависимости F(T) изменялся в пределах
1.0 < α < 1.4.
Кратко опишем некоторые
характерные особенности, выявленные при моделировании. Указываем только те
параметры, которые отличаются от опорного варианта.
3.3.1. Увеличение шага
движения (как при решении А, так и при решении Б)
R0 = r0 = 0.01
- Анимат не в состоянии найти даже локальный
экстремум, так как из-за большой величины шагов он не успевает почувствовать
разницы между различными точками. В итоге траектория представляет собой
блуждания по всей области поиска. Вероятность найти экстремум очень мала.
3.3.2. Уменьшение шага
движения (как при решении А, так и при решении Б)
R0 = r0 = 0.0001
- Анимат успешно находит локальный экстремум,
но из-за малой величины шага «притяжение» к первому найденному экстремуму
настолько велико, что анимат не может перейти к другому экстремуму.
3.3.3. Уменьшение величины
поворота
w0 = π/8
- Из-за малого значения w0 повороты довольно часто не приводят к существенному изменению
направления движения, в результате чего анимат перемещается на большие
расстояния и меньше блуждает в окрестности определенного экстремума.
- Анимат в состоянии обойти всю область
поиска и поэтому находит больше локальных экстремумов, чем при опорном
варианте.
w0 = π/16
- По сравнению с предыдущим вариантом, угол
поворота еще меньше. Это приводит к тому, что анимат ничего не может найти, он
все время куда-то движется, несколько раз пересекая всю область поиска.
3.3.4. Увеличение величины
поворота
w0 = π/3
- Анимат становится более инертным, ему
труднее перейти от уже найденного экстремума к другому. Он просто движется к
ближайшему экстремуму, а затем остается в его окрестности.
3.3.5. Влияние
стохастичности автомата
p = 0.9
- Поведение анимата практически не отличается
от опорного варианта. Он также в состоянии найти локальный экстремум или
несколько экстремумов.
p = 0.8
- Анимат, из-за своей стохастичности, может
пройти мимо одного из экстремумов, не заметив его. Это дает ему возможность
найти такие экстремумы, до которых детерминированный анимат просто не успевает
добраться.
p = 0.7
- В общих чертах поведение похоже на
предыдущие случаи. Там, где детерминированный анимат совершал блуждания вокруг
найденного экстремума, стохастический может прекратить блуждания и продолжить
поиск.
p = 0.6
- Этот случай уже существенно стохастический.
Блуждания вокруг найденных экстремумов сохраняются, но они охватывают большие
окрестности, что увеличивает вероятность перехода к новому поиску. Кроме этого,
становятся возможными блуждания там, где экстремума нет. Правда, такие
блуждания охватывают меньшие площади и заканчиваются гораздо быстрее.
3.3.6. Уменьшение глубины
памяти автомата n
n = 2
- Такой анимат проще «сбить с верного пути»,
поэтому он иногда выполняет ненужные остановки или начинает двигаться не в том
направлении.
- В то же время, такому анимату проще принять
решение в режиме поиска направления, поэтому он меньше стоит на месте и
способен исследовать большую площадь, а значит, найти больше локальных
экстремумов.
- При уменьшении глубины памяти анимат
становится менее инерционным.
3.3.7. Увеличение глубины
памяти автомата n
n = 4
- Такой анимат, в отличие от предыдущего, не
умеет «признавать» свои ошибки. Поэтому, начав искать направление нового поиска
и не найдя его сразу, он практически не в состоянии остановиться хотя бы на
каком-нибудь варианте и не может уйти от уже найденного экстремума.
- При увеличении глубины памяти анимат
становится более инерционным.
3.3.8. Увеличение шага
движения при решении А
R0 = 0.01, r0
= 0.001
- Благодаря довольно большим величинам шагов
в выбранном направлении, область поиска довольно велика. Она составляет
примерно одну десятую всей области.
- Движение, в отличие от опорного варианта,
уже не удается разделить на перемещения и блуждания. Находимые значения
максимума функции были выше, чем для опорного варианта (рис.9,10).
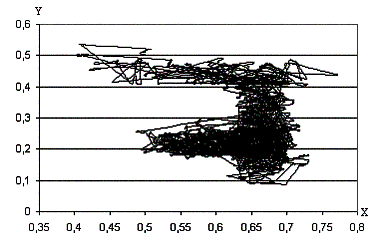
Рис. 9. Траектория анимата в координатах x,y.
R0 = 0.01, r0
= 0.001.
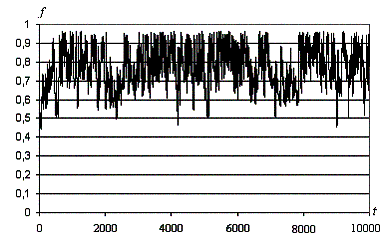
Рис. 10. Изменение значения оптимизируемой функции со временем f(t).
R0 = 0.01, r0
= 0.001.
3.3.9. Уменьшение шага
движения при решении Б
R0 = 0.001, r0
= 0.0001
- Из-за малых величин шагов, поиск происходит
лишь в малой окрестности центра области.
- Анимат находит только ближайший экстремум,
так как не успевает добраться до остальных.
3.3.10. Увеличение шага
движения при решении А, уменьшение шага движения при решении Б
R0 = 0.01, r0
= 0.0001
- Хотя можно считать, что в данном случае
повороты происходят практически на одном месте, поведение анимата очень похоже
на случай 3.3.8.
Итак, проведенное
компьютерное моделирование демонстрирует, что при достаточно естественном
выборе параметров (опорный вариант, варианты пп.3.3.5, 3.3.8, 3.3.10) поведение
модели качественно соответствует поисковому поведению животных. Введенное в
модель свойство инерционности позволяет анимату выходить из локальных
экстремумов и проводить поиск в значительной области пространства.
Заключение
Основные
результаты работы сводятся к следующему:
- Построена модель анимата, осуществляющего
поиск экстремума функции двух переменных.
- Анимат имеет
систему управления, которая содержит автомат (подобный автоматам с линейной
тактикой М.Л. Цетлина), этот автомат обеспечивает определенную инерционность в
принятии решения аниматом.
- Создана программа на основе языка
программирования Java, реализующая данную модель.
- Проведена серия компьютерных экспериментов
и показано, что при достаточно естественном выборе параметров модели поведение
анимата качественно соответствует поисковому поведению живых организмов.
Литература
1. Meyer
J.A., Wilson S. W. (Eds) From animals to animats. Proceedings of the First
International Conference on Simulation of Adaptive Behavior. The
MIT Press: Cambridge, Massachusetts, London, England. 1990.
2.
Редько В.Г. Эволюционная кибернетика. М.: Наука, 2001. 156
с. Гл. 7.
3. Непомнящих В.А. Аниматы как модель поведения животных // Сборник
материалов круглого стола конференции "Нейроинформатика-2002": М.:
МИФИ, 2003 – в печати, статья представлена на сайте:
http://www.keldysh.ru/pages/BioCyber/RT/Nepomn.htm
4. Непомнящих В.А.
Решение животными нечетко поставленных задач поиска и создание
искусственных поисковых агентов // Восьмая национальная конференция по
искусственному интеллекту с международным участием. Труды конференции. М.:
Физматлит, 2002. Т.2. С. 819-827.
5. Kuwana
Y., Shimoyama I., Sayama Y., Miura H. Synthesis of Pheromone-Oriented Emergent
Behavior of a Silkworm Moth // Proceedings of the 1996 IEEE/RSJ International
Conference on Intelligent Robots and Systems. 1996. P.1722-1729. См. также: http://www.leopard.t.u-tokyo.ac.jp
6. J.T.
Pierce-Shimomura, T.M. Morse, S.R. Lockery. The Fundamental Role of Pirouettes
in Caenorhabditis elegans Chemotaxis.
// The Journal of Neuroscience, 1999.
Vol.
19. N.
21. PP.
9557-9569.
7. V.A.
Nepomnyashchikh, K.A.
Podgornyj. The Model for Non-Brownian Searching Walk in
the Absence of Guiding Cues. Proceeding Supplement of the Sixth International
Conference on Simulation of Adaptive Behavior, Paris, 2000.
|