|
Классическая и эволюционная причинность в моделях обучения[1] Бурцев Михаил Сергеевич Институт прикладной математики им. М.В. Келдыша РАН mbur@narod.ru Введение Наиболее популярные методы обучения, используемые в моделях поведения животных [1-5] и при создании искусственных программных и робототехнических адаптивных систем [6, 7], основываются на предположении, что обучение однозначно детерминируется внешними или внутренними причинами. Такое понимание природы причин, приводящих к изменению поведения, аналогично пониманию причинности в классической физике, назовем этот тип причинности классическим или детерминистским. Подобный тип причинности не является единственно возможным [8-11], примерами современных научных теорий, в которых используются другие виды причинности, могут служить квантовая механика и эволюционная теория. Применение классической причинности при исследовании поведения животных критиковалось, как со стороны нейрофизиологии [12, 13], так и со стороны концептуальных подходов к проблемам самоорганизации и живого [8, 14] и обучения [15]. Возможно ли моделирование обучения основанного на причинности отличной от причинности используемой в большинстве современных моделей? Если да, то, как нужно строить такую модель, и какие проблемы при этом возникнут? Ниже будет приведена попытка формализовать два возможных различных типа причинности в обучении и сравнить их. Формализация причинности в обучении Для формализации процесса обучения используем автоматный подход [16]. Рассмотрим агента, имеющего внутреннюю среду и действующего во внешней среде. Представим "мозг", управляющий поведением агента, в виде автомата S{SE,SI,SS,SA,F} (см. рис.1). Здесь SE – множество элементов автомата, состояния которых определяются внешней по отношению к агенту средой; SI – элементы, определяющиеся внутренней средой агента; SS – внутренние элементы автомата; SA – элементы, определяющие действия агента; F – функция при помощи, которой вычисляются состояния элементов автомата. В каждый момент времени автомат описывается вектором состояний всех его элементов Sk.
Рис. 1. Схема автомата, управляющего поведением агента. SE – множество элементов автомата, состояния которых определяются внешней по отношению к агенту средой; SI – элементы, определяющиеся внутренней средой агента; SS – внутренние элементы автомата; SA – элементы, определяющие действия агента Будем считать, что наш автомат функционирует в дискретном времени t=(t0,t1,t2,…,tn). Подобное допущение принимается в большинстве моделей адаптивного поведения. Тогда поведение некоторого автомата Sk можно представить как:
или:
Таким образом, мы определили поведение через функцию, преобразующую состояния автомата S. В общем случае эта функция зависит от состояния внешней и внутренней среды агента в текущий момент времени, а так же от внутренних состояний самого автомата SS и SA в предыдущий момент времени. Если функция Fk некоторого автомата Sk не изменяется от одного момента времени к другому, то обучения не происходит. Назовем обучением процесс изменения функции F. Одновременное поведение и обучение рассматриваемого автомата можно записать следующим образом:
или:
здесь T – некоторое преобразование, действующее на множестве возможных функций F. Добавив в описание автомата преобразование T, получаем автомат с обучением S{SE,SI,SS,SA,F,T}. В общем виде преобразование T может действовать не только на F, но и на множество состояний автомата. Дополним (4) и запишем соотношения, определяющие поведение и обучение автомата:
В рамках приведенного формализма обучение определяется через задание вида функционала T, назовем его функционалом или алгоритмом обучения. Основная масса методов обучения, применяемых в искусственных нейронных сетях, а также алгоритмы обучения с подкреплением, не изменяют множество состояний автомата, т.е. преобразование T в этих моделях обучения действует только на F(см. формулу (4)). Обучение и классическая причинность Основное предположение, определяющее вид функционала T, в популярных методах обучения, заключается в том, что процесс обучения детерминируется собственными состояниями автомата. В большинстве алгоритмов T зависит от внутренних и внешних входов автомата, хотя в некоторых работах допускается зависимость от внутренних состояний автомата [17]. Следовательно, доминирующая парадигма основана на зависимости следующего вида:
т.е. изменение поведения (функции определяющей поведение) (4) является функцией от состояний самого автомата. Обучение и эволюционная причинность Какую альтернативу можно предложить классической причинности в обучении? Основное допущение альтернативного подхода к обучению заключается в следующем утверждении. Алгоритм обучения не зависит от состояний самого автомата. Попробуем построить такой алгоритм. Для того чтобы T не являлось функцией от S, представим его следующим образом:
здесь Теперь процессы поведения и обучения автомата Sk можно представить так:
Очевидно, что
если мы воспользуемся преобразованием (7) в общем виде, то автомат будет
эволюционировать к такому виду, в котором каждое действие будет выбираться
случайно с равной вероятностью. Следовательно, необходимо так изменить (7),
чтобы при сохранении независимости самого преобразования от состояний автомата,
не происходило деградации поведения. Заметим, что преобразование (7) является
формальным описанием порождения разнообразия, если мы будем рассматривать
процесс эволюции автоматов S. Шум Будем считать,
что отбор в процессе обучения реализуется за счет изменения амплитуды
шума-"мутаций"
где A – величина амплитуды шума. Причинность, задаваемая выражением (9) заключается в создании вариаций и отборе, назовем такой вид детерминации изменений эволюционным. Естественно, что отбор при обучении должен чем-то управляться, а значит, амплитуда шума должна от чего-то зависеть. Сделаем еще одно допущение конкретизирующее (7) и (9). Предположим, что отбор управляется самим агентом, а точнее состояниями его "мозга" S. Выразим это формально:
Выражение (10) значит, что агент самостоятельно решает, когда учиться, а когда нет. При этом после всех преобразований, выражение (10) соответствует основному тезису эволюционной причинности, что T не зависит ни от состояния внешней и внутренней среды агента, ни от состояния его "мозга". Внутренние состояния автомата S могут управлять лишь величиной преобразований при обучении, но не направленностью самого обучения. Другими словами, агент в каждый момент времени решает, стоит ли модифицировать свое поведение или нет, и если решено изменить поведение, то на основе уже имеющегося опыта генерируется новая случайная проба. Два противоположных подхода (6) и (10) к детерминации обучения обладают принципиально различными свойствами. Если в первом случае, обучение зависит от уже имеющегося опыта, направляется и ограничивается им, что приводит к "оптимизации" поведения в рамках уже известного агенту. В этом случае отсутствует возможность приобретения "новых" знаний. Напротив, при эволюционной детерминации обучения всегда присутствует случайность, которая служит источником новизны [18], обеспечивает "открытость" обучения, отсутствие границ процесса приобретения новых знаний. Открытые проблемы Хотя выражение (10) задает направление поиска альтернативных алгоритмов обучения основанных на эволюционной причинности, но для реализации конкретного метода обучения в виде модели его явно не достаточно. Для построения модели необходимо ответить, по крайней мере, на два вопроса. 1.
Как происходит воздействие "шума" на "мозг"? Или,
как операция 2. Как агент должен решать для себя, в каких ситуациях ему нужно учиться, а в каких нет? Или, каков вид зависимости A(SS)? Готовых ответов на эти вопросы сегодня не существует. Попытаемся наметить пути поиска возможных решений. Обучение будет эффективным, если уже имеющиеся знания не разрушаются, а используются для создания новых решений. В качестве алгоритма, соответствующего этим условиям, можно предложить следующий: 1. вставка новых элементов (внутренних состояний) в автомат; 2. установление функциональной зависимости (расширение F) между вставленными элементами и элементами, имеющими отношение к текущему поведению (при использовании в качестве автомата искусственной нейронной сети это, например, могут быть нейроны с наибольшей активацией). Такой алгоритм должен приводить в модели к явлению похожему на специализацию нейронов в мозге животных. Также этот алгоритм вставки может быть проинтерпретирован в терминах теории функциональных систем [19]. Можно сказать, что этот алгоритм описывает системогенез, в процессе которого, происходит создание новых пробных интеграций (функциональных систем) за счет добавления новых элементов, выступающих в роли акцептора результата действия. Для поиска ответа на вопрос о том, когда стоит учиться, а когда нет, сделаем допущение, что обучение происходит только в том случае, когда уже имеющихся знаний не хватает для генерации необходимого поведения. В теории функциональных систем такая ситуация соответствует невозможности достижения необходимого результата при помощи имеющегося репертуара функциональных систем. Однако, механизмы подобной оценки невозможности достижения результата мозгом животных практически не исследованы (что выступает в качестве дополнительного стимула к попыткам их моделирования). Для поиска A(SS) можно попытаться использовать эволюционное моделирование в надежде на то, что в процессе искусственной эволюции будет найдено решение функционально гомологичное существующему в природе. Для этого в автомате необходимо ввести специальный выход, который будет управлять амплитудой стохастического поиска. Функциональная зависимость этого выхода от внутренних состояний автомата будет находиться в процессе эволюции обучающихся агентов. Основные особенности популярных алгоритмов и предложенной альтернативы сведены в таблицу 1. Таблица 1.
Предложенный подход к моделированию обучения обладает рядом существенных отличий от наиболее распространенных моделей обучения. Это делает актуальной задачу его реализации в виде компьютерной модели, и последующего сравнения его динамики с динамикой обучения реальных животных и других моделей (в том числе с динамикой моделей, лежащих в области синтеза теории функциональных систем и обучения с подкреплением [20]). Успехи методов эволюционного синтеза искусственных нейронных сетей [21, 22], которые концептуально близки к предложенному методу обучения, позволяют надеяться, что будут получены интересные результаты.
Список литературы 1. Dayan, P. and Balleine, B. W. Reward, motivation, and reinforcement learning // Neuron 36[2], 285-298. 2002. 2. Suri, R. E., Bargas, J., and Arbib, M. A. Modeling functions of striatal dopamine modulation in learning and planning // Neuroscience 103[1], 65-85. 2001. 3. Spier, E. and McFarland, D. Possibly optimal decision-making under self-sufficiency and autonomy // J.Theor.Biol. 189[3], 317-331. 1997. 4. Balkenius, C. and Moren, J. Dynamics of a classical conditioning model // Autonomous Robots 7, 41-56. 1999. 5. Joel, D., Niv, Y., and Ruppin, E. Actor-critic models of the basal ganglia: new anatomical and computational perspectives // Neural Netw. 15[4-6], 535-547. 2002. 6. Sutton, Richard S. and Barto, Andrew G. Reinforcement learning an introduction. Cambridge, Mass, MIT Press, 1998. 7. Blumberg, B. Old Tricks, New Dogs: Ethology and Interactive Creatures. Ph.D. MIT Media Lab, 1996. 8. Пригожин И. Конец определенности. Время, хаос и новые законы природы. Ижевск, Ижевская республиканская типография, 1999. 216 c 9. Поппер К.Р. Мир предрасположенностей: два новых взгляда на причинность. // Эволюционная эпистемология и логика социальных наук: Карл Поппер и его критики. Под ред. Садовского В.Н., Эдиториал УРСС, 2000. стр 176-193 10. Причинность и телеономизм в современной естественно-научной парадигме // под ред. Мамчура Е.А. и Сачкова Ю.В. М., Наука, 2002. 11. Campbell, Donald T. and Bickhard, Mark H. Variations in Variation and Selection: The Ubiquity of the Variation-and-Selective-Retention Ratchet in Emergent Organizational Complexity // Foundations of Science 8[3], 215-282. 2003. 12. Сахаров Д.А. Уроки малых сетей. Лекция на семинаре "Мозг", Москва 23-03-2004. См. http://www.neurogene.ru/. 13. Анохин П.К. Проблема центра и периферии в современной физиологии нервной деятельности // Проблема центра и периферии в нервной деятельности. Горький, 1935. стр 9-70 14. Поппер К.Р. Об облаках и часах // Объективное знание. Эволюционный подход. М., Эдиториал УРСС, 2002. стр 200-247 15. Поппер К.Р. Эволюционная эпистемология // Эволюционная эпистемология и логика социальных наук: Карл Поппер и его критики. Под ред. Садовского В.Н., Эдиториал УРСС, 2000. стр 57-74 16. Цетлин М.Л. Исследования по теории автоматов и моделированию биологических систем. М., Наука, 1969. 316 с. 17. Ziemke, T. On 'Parts' and 'Wholes' of Adaptive Behavior: Functional Modularity and Diachronic Structure in Recurrent Neural Robot Controllers // From animals to animats 6 - Proceedings of the Sixth International Conference on the Simulation of Adaptive Behavior. Cambridge, MA, MIT Press, 2000. 18. Чернавский Д.С. Синергетика и информация: Динамическая теория информации. М., Наука, 2001. стр. 106-107 19. Анохин П.К. Принципиальные вопросы общей теории функциональных систем // Принципы системной организации функций. М., Наука, 1973. стр. 5-61 20. Red'ko V.G., Prokhorov D.V., Burtsev M.S. Theory of Functional Systems, Adaptive Critics and Neural Networks // Proceedings of the International Joint Conference on Neural Networks (IJCNN ’04), Hungary, Budapest 21. Ruppin, E. Evolutionary autonomous agents: a neuroscience perspective // Nat.Rev.Neurosci. 3[2], 132-141. 2002. 22. Nolfi, S. and Floreano, D. Synthesis of autonomous robots through evolution // Trends Cogn Sci. 6[1], 31-37. 2002. |

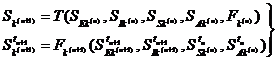 . (5)
. (5)