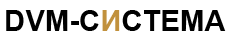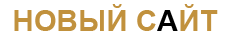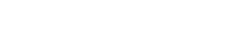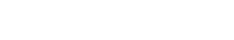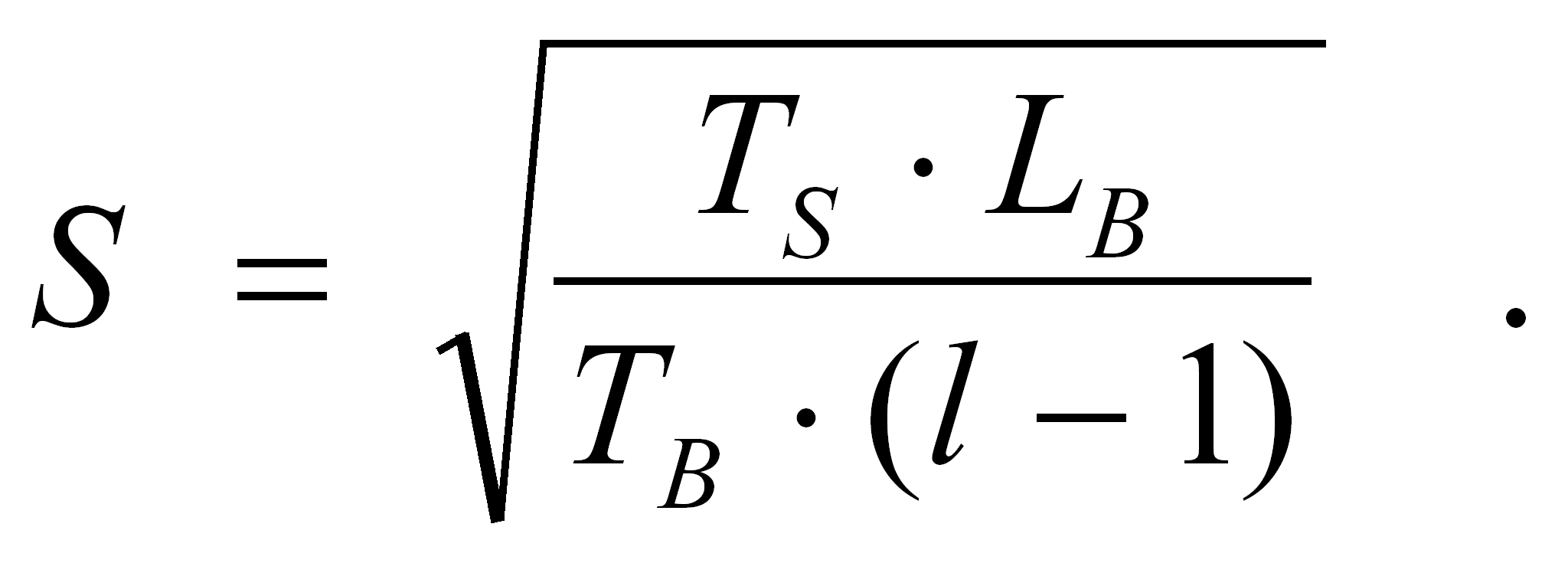
Рис.1. DVM-модель распределения данных по процессорам.
|
Предсказатель
производительности DVM-программ |
|
- дата последнего обновления19.10.10 -
Оглавление
1 Введение
2
Принципы реализации Предиктора.
2.1
Представление программы в виде иерархии интервалов
2.2
Характеристики выполнения программы на каждом процессоре
2.3
Основные характеристики и их компоненты
2.4
Исходные данные для Предиктора.
2.5
Опции командной строки Предиктора
3
Моделирование.
3.1
Общие принципы моделирования.
3.2
Обычные функции
3.3
Функции начала/конца интервала
3.4
Функции ввода/вывода данных.
3.5
Функции создания/уничтожения объектов
3.6
Функции распределения ресурсов и
данных
3.7
Функции инициализации коллективных операций
3.8
Функции выполнения коллективных операций
3.9
Функции организации параллельного цикла
3.10
Неизвестные функции
4
Оценка накладных расходов доступа к удаленным данным
4.1
Основные понятия и термины
4.2
Оценка обменов при перераспределении массивов
4.3
Оценка обменов границами распределенных массивов.
4.4
Оценка обменов при выполнении операций редукции
4.5
Оценка обменов при загрузке буферов удаленными элементами
массивов.
4.6
Оценка обменов при оптимальном времени выполнения параллельного цикла
с зависимостями по данным (across циклы)
5.
Поиск оптимальной конфигурации процессоров
Приложение
1. Тест на определение производительности процессоров.
Приложение
2. Связь имен полей в выходном HTML-файле и имен полей в структуре
_IntervalResult.
Приложение
3. Описание вспомогательных функций и классов
Приложение
4. Основные функции экстраполятора времени
Приложение
5. Фрагменты трассы и параметры моделируемых Предиктором функций
Lib-DVM
Литература
Предиктор предназначен для анализа и отладки производительности DVM-программ без использования реальной параллельной машины (доступ к которой обычно ограничен или сложен). С помощью Предиктора пользователь имеет возможность получить оценки временных характеристик выполнения его программы на MPP или кластере рабочих станций с различной степенью подробности.
Реализация Предиктора представляет собой систему обработки трассировочной информации собранной библиотекой периода выполнения Lib-DVM во время прогона программы на рабочей станции и состоит из двух крупных компонент: интерпретатора трассы (PRESAGE) и экстраполятора времени (RATER). По данным трассировки и параметрам, заданным пользователем, интерпретатор трассы вычисляет и выдает ему экстраполированные временные характеристики выполнения данной программы на MPP или кластере рабочих станций, вызывая функции экстраполятора времени, который в свою очередь моделирует параллельное выполнение DVM-программ, являясь по сути моделью библиотеки Lib-DVM, низлежащей системы передачи сообщений и аппаратуры.
Производительность параллельных программ на многопроцессорных ЭВМ с распределенной памятью определяется следующими основными факторами:
Степенью распараллеливания программы - долей параллельных вычислений в общем объеме вычислений.
Равномерностью загрузки процессоров во время выполнения параллельных вычислений.
Временем, необходимым для выполнения межпроцессорных обменов.
Степенью совмещения межпроцессорных обменов с вычислениями.
Эти и многие другие характеристики, необходимые программисту для оценки качества параллельной программы являются результатом работы Предиктора.
Концептуально работа программы подразделяется на три основных этапа:
Чтение трассировки, извлечение из нее информации о структуре интервалов, о последовательности и вложенности вызовов функций системы поддержки, о тех входных и возвращаемых параметрах вызовов функций, которые необходимы для их моделирования, а также о времени, затраченном на выполнение каждого из вызовов;
Моделирование выполнения программы на основе полученной на предыдущем этапе структуры выполнения программы и вычисление описанных в разделе 2.2.1 характеристик выполнения программы на каждом из интервалов;
Запись вычисленных характеристик в файл в формате HTML.
2 Принципы реализации Предиктора
2.1 Представление программы в виде иерархии интервалов
Для более детального анализа эффективности программы пользователю предоставлены средства разбиения выполнения программы на интервалы и возможности получения характеристик производительности для каждого из них.
Выполнение программы можно представить в виде последовательности чередующихся интервалов (групп операторов) ее последовательного и параллельного выполнения. По умолчанию, вся программа является одним интервалом. Интервалы задаются пользователем специальными операторами языков C-DVM и Fortran-DVM, либо режимом компиляции, при котором интервалами являются
все параллельные циклы;
все последовательные циклы, содержащие внутри себя параллельные циклы;
все последовательные циклы вообще.
(Ограничение: при использовании Предиктора не допускается задание целочисленного выражения с интервалом внутри параллельного цикла).
Пользователь может разбить любой интервал на несколько подинтервалов или объединить несколько соседних (по порядку выполнения) интервалов в новый единый интервал (т.е. представить программу в виде иерархии интервалов нескольких уровней; самый высокий уровень всегда имеет вся программа целиком - уровень 0).
Механизм разбиения программы на интервалы служит для более детального анализа поведения программы во время ее выполнения. При просмотре результатов с помощью Предиктора, пользователь имеет возможность задать глубину детализации, то есть исключить из рассмотрения интервалы, начиная с некоторого уровня вложенности.
Для упрощения дальнейшего описания введем следующие понятия. Интервал будем называть простым, если он не содержит внутри себя других интервалов (вложенных интервалов). Интервалы, включающие в себя вложенные интервалы, будем называть составными. Таким образом, программа в целом представляет собой дерево интервалов: интервал самого высокого уровня, представляющий всю программу, является его корнем; тот из них, который имеет самый низкий уровень, является интервалом листом.
Во время обработки трассировочной информации один из интервалов являются активным интервалом (т.е. интервалом, в котором находится исполняемый в данный момент оператор программы и являющийся самым «нижним» в дереве интервалов). Для него в это время собирается следующая информация:
тип интервала (IntervalType);
количество вхождений в интервал (EXE_count);
имя файла (source_file) с исходным текстом программы;
и номер строки в нем (source_line), соответствующей началу интервала.
На этом же этапе подсчитывается количество коммуникационных операций, выданных программой внутри данного интервала:
количество операций ввода/вывода (num_op_io);
количество операций редукции (num_op_reduct);
количество операций обмена границами (num_op_shadow);
количество операций удаленного доступа к элементам массива (num_op_remote);
количество операций перераспределения массивов (num_op_redist);
В Предикторе каждому интервалу соответствует объект типа «Interval», который содержит в себе необходимые характеристики интервала; в процессе интерпретации трассы строится дерево интервалов. Каждый интервал включает в себя вектор подобъектов «Processor», элемент которого хранит характеристики процессора, участвующего в выполнении интервала (заметим, что в условиях задачного параллелизма не все процессоры могут принимать участие в выполнении какого-либо интервала). Таким образом, после завершения этапа интерпретации трассы имеется дерево интервалов с узлами «Interval» с накопленными характеристиками (IntervalType, EXE_count, source_file, source_line, num_op_io, num_op_reduct, num_op_shadow, num_op_remote, num_op_redist). В то же самое время осуществляется сбор характеристик для каждого процессора, исполняющего интервал, в соответствующем ему объекте «Processor».
2.2 Характеристики выполнения программы на каждом процессоре
Объект “Processor” хранит следующие характеристики процессора, участвующего в выполнении интервала:
Execution_time – время выполнения интервала.
IO_time - время ввода-вывода.
SYS_time – полезное системное время, время, проведенное процессором в системной фазе (т.е. время, затраченное Lib-DVM, без учета времени передачи сообщений).
CPU_time - полезное процессорное время - время, проведенное процессором в пользовательской фазе (т.е. на пользовательских вычислениях с учетом “нарезания” циклов).
Lost_time - потерянное время - сумма составляющих – потерь из-за недостаточного параллелизма (Insuff_parallelism), коммуникаций (Communication) и простоев (Idle).
Communication – общее время коммуникаций. Время каждого типа коммуникаций экстраполируется экстраполятором времени (RATER).
Insuff_parallelism = Insuff_parallelism_USR + Insuff_parallelism_SYS.
Insuff_parallelism_USR – пользовательские потери из-за недостаточного параллелизма.
Insuff_parallelism_SYS – системные потери из-за недостаточного параллелизма.
Synchronization – потери из-за рассинхронизации.
Time_variation - потери из-за разброса времен завершения коллективных операций.
Idle – простои на данном процессоре - разность между максимальным временем выполнения интервала (поиск по всем процессорам) и временем его выполнения на данном процессоре.
Load_imbalance – разбалансировка, вычисляется как разность между максимальным процессорным временем (CPU+SYS) и соответствующим временем на данном процессоре.
Overlap – суммарное время перекрытия асинхронных коммуникационных операций; вычисляется как (см. ниже) сумма времен перекрытия асинхронных операций ввода/вывода (IO_overlap), редукции (Reduction_overlap), обмена границами (Shadow_overlap), удаленного доступа к элементам массивов (Remote_overlap) и перераспределения массивов (Redistribution_overlap).
IO_comm – суммарное время коммуникаций для операций ввода/вывода.
IO_synch - потери из-за рассинхронизации для операций ввода/вывода.
IO_overlap - время перекрытия асинхронных операций ввода/вывода.
Wait_reduction - суммарное время коммуникаций для операций редукции.
Reduction_synch - потери из-за рассинхронизации для операций редукции.
Reduction_overlap - время перекрытия асинхронных операций редукции.
Wait_shadow - суммарное время коммуникаций для операций обмена границами.
Shadow_synch - потери из-за рассинхронизации для операций обмена границами.
Shadow_overlap - время перекрытия асинхронных операций обмена границами.
Remote_access - суммарное время коммуникаций для операций удаленного доступа к элементам массивов.
Remote_synch - потери из-за рассинхронизации для операций удаленного доступа к элементам массивов.
Remote_overlap - время перекрытия асинхронных операций удаленного доступа к элементам массивов.
Redistribution - суммарное время коммуникаций для операций перераспределения массивов (redistribute, realign).
Redistribution_synch - потери из-за рассинхронизации для операций перераспределения массивов.
Redistribution_overlap - время перекрытия асинхронных перераспределения массивов.
Как уже отмечалось выше, сбор этих характеристик осуществляется на первом этапе моделирования – этапе интерпретации трассы; они сохраняются в объекте “Processor”, существующем для каждого интервала и каждого процессора, исполняющего данный интервал.
В процессе интерпретации трассы строится “дерево интервалов” (дерево объектов “Interval”), каждый из которых содержит вектор объектов “Processor”. Размер вектора равен числу процессоров в корневой процессорной топологии, но “значащими” элементами являются те, которые соответствуют процессорам, на которых выполняется интервал.
2.3 Основные характеристики и их компоненты
Возможность интерпретировать трассу, накопленную Lib-DVM на этапе модельного выполнения программы, позволяет Предиктору выдать пользователю следующие основные показатели выполнения параллельной программы как для всей программы в целом, так и для каждого ее интервала:
время выполнения (Execution_time) - это максимальное из времен выполнения параллельной программы, найденное по всем используемым ею процессорам.
коэффициент эффективности (Efficiency) - главная характеристика параллельного выполнения программы. Для его нахождения вычисляются два времени:
Полезное время (Productive_time), это время, которое потребуется для выполнения параллельной программы на однопроцессорной ЭВМ (это время можно разложить на три компоненты):
полезное пользовательское время (Productive_CPU_time) – время, которое программа потратила на нужные “пользовательские” вычисления.
полезное системное время (Productive_SYS_time) - время, которое программа потратила на нужные “системные” вычисления (обращения к Lib-DVM).
время ввода-вывода (IO_time) - время, которое программа потратила на ввод/вывод.
Общее время (Total_time) использования процессоров, которое вычисляется как произведение времени выполнения на общее число используемых процессоров.
Коэффициент эффективности равен отношению полезного времени к общему времени использования процессоров.
потерянное время (Lost_time) - разница между общим временем использования процессоров и полезным временем представляет собой потерянное время. Существуют следующие составляющие потерянного времени:
Недостаточный параллелизм (Insuff_parallelism) - потери из-за недостатка параллелизма, приводящего к дублированию вычислений на нескольких процессорах.
Коммуникации (Communication) - потери из-за выполнения межпроцессорных обменов.
Простои (Idle) - потери из-за простоев тех процессоров, на которых выполнение программы завершилось раньше, чем на остальных.
cинхронизация (Synchronization) – служит для оценки суммарных потенциальных потерь, которые могут возникнуть из-за неодновременного запуска коллективных операций на разных процессорах. Основная причина рассинхронизации – это разбалансировка загрузки процессоров при выполнении параллельных циклов. Для оценки возможных потерь из-за разбалансировки программисту выдается обобщенная характеристика – разбалансировка.
разбалансировка (Load_imbalance). Рассинхронизация может возникать не только из-за разбалансировки, но также из-за различий во временах завершения выполнения на разных процессорах одной и той же коллективной операции, вызванных особенностями ее реализации на конкретной параллельной ЭВМ.
разброс времен (Time_variation) завершения коллективных операций используется программистом для оценки величины потенциальной рассинхронизации.
время перекрытия (Overlap) обменов вычислениями является важной характеристикой, отражающей степень совмещения межпроцессорных обменов с вычислениями. Вычисляется как сумма времен перекрытия при выполнении четырех операций: удаленного доступа, редукции, обновления теневых граней и перераспределения.
Более подробно сущность вышеперечисленных характеристик описана в работе [1].
После того, как дерево объектов “Interval” построено, для каждого объекта вызывается метод “Integrate”, который осуществляет расчет характеристик интервала по соответствующим характеристикам вектора процессоров и по характеристикам вложенных интервалов. В заключение по дереву интервалов создается HTML-файл путем вписывания вычисленных значений в специальный “шаблон”, соответствующий одному интервалу (смотри файл IntervalTemplate.cpp). Соответствие полей объекта “Interval” и видимых полей HTML-файла приведено в Приложении 1.
2.4 Исходные данные для Предиктора
Исходными данными для моделирования служат трассировка выполнения данной программы на одном процессоре, конфигурационная информация, записанная в каком либо файле (например, “Predictor.par”) и параметры командной строки. Для получения трассы нужного содержания в конфигурационный файл usr.par необходимо внести следующие параметры:
|
Is_DVM_TRACE=1; |
- трассировка включена; |
|
FileTrace=1; |
- накапливать трассировку в файлах; |
|
MaxIntervalLevel=3; |
- максимальный уровень вложенности интервалов; |
|
PreUnderLine=0; |
- не подчеркивать call в файле трассы; |
|
PostUnderLine=0; |
- не подчеркивать ret в файле трассы; |
|
MaxTraceLevel=0; |
- максимальная глубина трассы для вложенных функций |
Параметры PreUnderLine, PostUnderLine и MaxTraceLevel являются указанием Lib-DVM на то, что не надо накапливать в трассе строки, состоящие из подчеркиваний, а также не надо трассировать вложенные вызовы функций Lib-DVM, что приводит к существенному сокращению размера файла трассы.
Замечание. При запуске на одном процессоре параллельной программы, в которой явно указана требуемая ей конфигурация процессоров или предусмотрена динамическая настройка на выделенное количество процессоров, необходимо задать соответствующую “виртуальную” процессорную систему с помощью параметров IsUserPS и UserPS.
Например, для задания “виртуальной” процессорной системы 2*2 значения параметров будут следующими:
|
IsUserPS=1; |
- использовать задание “виртуальной” процессорной системы; |
|
UserPS=2,2; |
- топология “виртуальной” процессорной системы. |
Замечание. При запуске с целью получения трассы для предиктора автоматически подключается файл “pred_trc.par”, где задаются параметры для трассировки различных сообщений. При этом отметим следующие важные параметры
|
Is_DVM_STAT=1; |
- |
хотя он задает сбор статистики, но он также влияет на попадание информации об интервалах в трассу. |
|
LoadWeightTrace=1; |
- |
информация о векторе весов распределения массива с помощью WGTBLOCK |
Рассмотрим фрагмент трассировки:
1. call_getlen_
TIME=0.000005 LINE=31 FILE=GAUSS_C.CDV
2.
ArrayHandlePtr=951cd0;
…
3.
ret_getlen_ TIME=0.000002 LINE=31 FILE=GAUSS_C.CDV
4.
Res=4;
Строка 1 является строкой, идентифицирующей вызываемую функцию Lib-DVM (getlen_). Она содержит:
время выполнения пользовательской части программы (т.е. величину интервала времени от предыдущего возврата из Lib-DVM до вызова данной функции - TIME=0.000005; это время (назовем его call_time) обычно суммируется в поле CPU_Time структуры “Interval” в процессе интерпретации трассы);
номер строки исходного файла программы (LINE=31), в которой находится вызов функции Lib-DVM и которая переносится в поле source_line структуры “Interval”;
имя исходного файла программы (FILE=GAUSS_C.CDV), в котором находится вызов функции Lib-DVM и которое переносится в поле source_file структуры “Interval”;
Строка 2 (и возможно последующие строки) содержат имена и значения фактических параметров вызываемой функции. Они преобразуются в соответствующие исходные числовые значения, пакуются в структуры и используются при интерпретации каждой функции Lib-DVM.
Строка 3 трассирует возврат из функции Lib-DVM. Единственное значение, которое используется Предиктором – это время (назовем его ret_time) выполнения функции (TIME=0.000002); обычно оно суммируется в поле SYS_Time структуры “Interval”.
Строка 4 содержит возвращаемое функцией значение и используется аналогично строке 2.
Заметим, что каждая функция Lib-DVM обрабатывается Предиктором по своему алгоритму, хотя многие из них (так называемые “неизвестные” и “обычные” функции) обрабатываются по одному и тому же “основному” алгоритму.
Конфигурационная информация, записанная в файле “predictor.par” определяет характеристики целевой (моделируемой) многопроцессорной системы и имеет следующую структуру:
cluster
= mvs;
// search optimal processor set 0=off
1=euristik
search=0;
// Cluster
properties:
// string = { [int 'x']string [,[int
'x']string]*} | float
// string.CommType = ethernet | transputer |
myrinet (num_channels) | string.CommType
// Communication
characteristics (mks)
// string.TStart = float
// string.TByte
= float
mvs = {512
x mvsP2};
mvs.CommType = myrinet (1);
mvs.TStart = 7;
mvs.TByte
= 0.004;
mvsP2
= {2 x mvsP1};
mvsP2.CommType = myrinet (1);
mvsP2.TStart =
1;
mvsP2.TByte
= 0.001;
mvsP1 = 1.00;
Предложения, начинающиеся с “//” являются комментариями.
Параметр Cluster указывает какой из кластеров, описанных ниже считать целевым. Это сделано для удобства и для ограничения количества процессоров при поиске оптимальной конфигурации процессоров.
Параметр search позволяет выполнить поиск оптимальной конфигурации процессоров, исходя из общего количества процессоров, заданных в кластере (параметром cluster и параметрами дальнейшего уточнения его структуры). По умолчанию параметр search равен 0 (отключен). Эвристический поиск оптимальной конфигурации задается значением 1. Результаты предсказания программы на оптимальной конфигурации записываются в файл best.html.
Дальнейшая структура кластеров, описывается при помощи двух способов
Если кластер состоит из подкластеров (т.е. не из одного процессора), то его описание перечисляется в фигурных скобках через запятую. Перед именем подкластера может стоять число, указывающее на количество таких подкластеров входящих в данный кластер. Структура целевого кластера должна иметь иерархическую структуру (т.е. вложенные кластеры не должны описываться через своих предков).
Если кластер состоит из одного процессора, то надо указать отношение его производительности к производительности процессора инструментальной машины, на которой была получена трассировка для предиктора. Если такой параметр не указан, то по умолчанию считается равным 1. Для определения производительности процессоров разработан тест (см. Приложение 1.)
Если кластер состоит из подкластеров, то для него надо указать параметр CommType, который задает тип коммуникационной сети, связывающей подкластеры между собой. Значение ethernet говорит о том, что система подкластеров объединена в сеть с шинной организацией; значение transputer указывает на то, что для коммуникаций между подкластерами используется система транспьютерного типа; а значение myrinet(num_channels) используется в случаях, когда передача данных между подкластерами осуществляется по нескольким каналам сети myrinet. При этом возможен вариант, когда для задания CommType используется имя коммуникационной среды другого кластера и тогда в качестве параметров новой среды возьмутся такие же параметры. Это следует рассматривать как сокращение записи параметров.
TStart и TByte являются характеристиками коммуникационной среды между подкластерами и равны соответственно ее латентности и пропускной способности. Эти характеристики используются для вычисления времен передач сообщений. Например для сети рабочих станций при вычислении времени передачи n байт используется линейная апроксимация
T = TStart + n * TByte,
где:
|
TStart |
- латентность (стартовое время передачи данных), |
|
TByte |
- пропускная способность (время передачи одного байта). |
Структура выходного HTML-файла совпадает со структурой интервалов в программе. Каждому интервалу соответствует свой параграф, в котором записаны данные, характеризующие данный интервал и интегральные характеристики выполнения программы на данном интервале и ссылки на параграфы с информацией о вложенных интервалах. Для навигации по файлу в конце каждого параграфа имеются соответствующие кнопки.
Запуск предиктора может осуществляться в режиме командной строки командой:
predictor <par_file> <trace_file> <html_file> [<processor>]
где:
|
<par_file> |
- |
имя файла с конфигурационной информацией о целевой ЭВМ; |
|
<trace_file> |
- |
имя файла с накопленной трассировкой; |
|
<html_file> |
- |
имя файла, куда выводится HTML-страница с результатами работы программы; |
|
<processor> |
- |
топология процессора, т.е. число процессоров по каждому из измерений решетки процессоров. Данный параметр аналогичен параметру topology конфигурационного файла и “перебивает” последний. |
Все параметры командной строки, кроме <processor> являются обязательными.
Для удобства запуска предиктора существует команда:
dvm pred [матрица процессоров] <имя_DVM-программы>
Выполнение команды управляется переменными окружения (см. файл dvm.bat):
Pred_sys - имя конфигурационного файла, описывающего целевую машину;
Pred_vis - имя программы Web–браузера.
Предиктор проверяет наличие в текущей директории файла <имя_DVM-программы>.ptr. Если файл есть, то он используется.
Если файла нет, то ищется файл <имя_DVM-программы>0_0.ptr, по которому определяется: на каком количестве процессоров запускалась задача, и идет объединение соответствующих трасс (<имя_DVM-программы>0_0.ptr и <имя_DVM-программы>1_1.ptr) в <имя_DVM-программы>.ptr. Если при объединении какой-то трассы не хватает, то выдается сообщение об ошибке. Далее предиктор работает с трассой <имя_DVM-программы>.ptr.
Если в текущей директории нет файлов с именами <имя_DVM-программы>.ptr и <имя_DVM-программы>0_0.ptr, а в <имя_DVM-программы> входит символ @, то производится сбор всех файлов из данной директории, удовлетворяющих заданной маске (где символ ‘@’ обозначает любую последовательность символов) в одну трассу.
Результат работы:
файл best.html, если был указан параметр поиска оптимальной конфигурации процесоров (search = 1 в файле конфигурации процессорной системы).
файл <имя_DVM-программы><[матрица процессоров]>.html с характеристиками выполнения программы в виде html-страницы.
Если задан Web - браузер (например, Netscape), то он автоматически вызывается и открывает страницу с результатами предсказания выполнения <имя_DVM-программы> на указанной матрице процессоров. Выполнение команды в этом случае завершается после завершения работы браузера.
3.1 Общие принципы моделирования
Первым этапом моделирования является построение call-графа вызовов функций Lib-DVM c фактическими параметрами. Такой граф является линейной последовательностью call-ов, т.к. вложенные вызовы не обрабатываются (и даже не накапливаются в трассе, собранной для работы Предиктора. Построение call-графа выполняется за три шага:
Файл трассы ->
вектор объектов TraceLine ->
вектор объектов FuncCall
На втором этапе работы программы осуществляется собственно моделирование выполнения программы на заданной многопроцессорной системе.
Для вычисления характеристик выполнения программы производится моделирование вызовов функций Lib-DVM в той же последовательности, в которой они находились в трассировке. В ходе моделирования используются следующие вспомогательные структуры и массивы структур:
структура с информацией о моделируемой процессорной системе;
массив структур с информацией о существующих на данный момент представлениях абстрактных машин;
массив структур с информацией о существующих на данный момент распределенных массивах;
структура с информацией о последнем созданном параллельном цикле;
массив структур с информацией о существующих на данный момент редукционных переменных;
массив структур с информацией о существующих на данный момент редукционных группах;
массив структур с информацией о существующих на данный момент группах обновления теневых граней;
массив структур с информацией о стартовавших, но еще не завершившихся редукциях;
массив структур с информацией о стартовавших, но еще не завершившихся обновлениях теневых граней;
стек виртуальных машин (и соответственно текущая виртуальная машина), соответствующий динамически создаваемым виртуальным машинам и “входам в них”.
Элементы массивов создаются и уничтожаются по мере последовательного моделирования вызовов в соответствии с тем, как это происходило при выполнении программы.
Все функции системы поддержки с точки зрения их моделирования можно условно разделить на следующие классы:
обычные функции;
функции начала/конца интервала;
функции ввода/вывода данных;
функции, связанные с передачей данных;
функции создания/уничтожения объектов;
функции распределения ресурсов и данных;
функции инициализации коллективных операций;
функции выполнения коллективных операций;
функции организации параллельного цикла;
неизвестные функции.
В последующих разделах будут детально рассмотрены принципы моделирования функций, входящих в данные классы.
В данную группу входят функции, выполняющиеся на каждом из процессоров моделируемой параллельной системы (или той ее подсистемы, на которую отображена текущая задача), причем время их выполнения не зависит от конфигурационных параметров и совпадает со временем выполнения на однопроцессорной машине (учетом отношения производительности процессоров. Если для функции Lib-DVM не указано явно, то такая функция априори моделируется по данному алгоритму.
Моделирование: времена call_time и ret_time прибавляются к Execution_time, время call_time к CPU_time, а ret_time к SYS_time каждого из процессоров. Кроме того, к Insuff_parallelism_USR каждого процессора прибавляется время, рассчитанное по формуле:
T = Tcall_time * (Nproc - 1) / Nproc
а к Insuff_parallelism_SYS прибавляется время
T = Tret_time * (Nproc - 1)/ Nproc
Данный алгоритм моделирования времени является основным. Далее будем предполагать, что время выполнения моделируются по этому алгоритму, за исключением тех случаев, когда при описании моделирования функции явно указан отличный от этого алгоритм.
3.3 Функции начала/конца интервала
В данную группу входят функции, служащие ограничителями интервалов, из которых состоит моделируемая программа.
Функции:
|
binter_ |
- |
Создание пользовательского интервала |
|
bploop_ |
- |
Создание параллельного интервала |
|
bsloop_ |
- |
Создание последовательного интервала |
Алгоритм моделирования: в массиве интервалов, вложенных в текущий интервал, ищется интервал с таким же именем файла с исходным текстом, таким же номером строки и значением выражения (если требуется) и таким же типом, как и в трассе (source_file, source_line). Тип интервала определяется исходя из того, какая именно функция начала интервала встретилась в трассировке, в соответствии со следующей таблицей:
|
binter_ |
Пользовательский (USER) |
|
bsloop_ |
Последовательный (SEQ) |
|
bploop_ |
Параллельный (PAR) |
Если такой интервал найден, то значение EXE_count для данного интервала увеличивается на 1, в противном случае создается новый элемент в массиве вложенных в текущий интервал интервалов с равным 1 значением EXE_count. После этого найденный или созданный интервал становится текущим.
Функции:
|
einter_ |
- |
закрытие пользовательского интервала; |
|
eloop_ |
- |
закрытие последовательного и параллельного интервалов. |
Алгоритм моделирования: текущим становится внешний по отношению к текущему интервал. Осуществляется коррекция времен в соответствии с основным алгоритмом.
3.4 Функции ввода/вывода данных
В данную группу входят функции, предназначенные для ввода/вывода данных. Такие функции выполняются на процессоре ввода-вывода.
Алгоритм моделирования: алгоритм моделирования времени отличается от основного. Время выполнения функции прибавляется к Execution_time и к IO_time только процессора ввода-вывода. Некоторые из этих функций рассылают результат выполнения по всем процессорам. В таком случае время рассылки прибавляется к IO_comm всех процессоров.
3.5 Функции создания/уничтожения объектов
В данную группу входят функции, создающие и уничтожающие различные объекты библиотеки поддержки Lib-DVM. Когда одна из таких функций встречается в трассировке, необходимо либо создать и инициализировать, либо удалить соответствующий объект в моделируемой многопроцессорной системе. Как правило, создание и уничтожение объектов осуществляется соответствующими конструкторами и деструкторами экстраполятора времени (RATER).
Функция:
|
crtps_ |
- создание подсистемы заданной многопроцессорной системы. |
Ввиду того, что пуск подзадачи осуществляется вызовом
long runam_ (AMRef *AMRefPtr)
где *AMRefPtr - ссылка на абстрактную машину запускаемой подзадачи,
а завершение выполнения (останов) текущей подзадачи – вызовом
stopam_ ()
в Предикторе поддерживается стек пар (AM, PS) (где runam_ приводит к загрузке стека парой (AM, PS), а stopam_ - к выгрузке). Вершиной стека определяется текушее состояние системы: текушая АМ и текущая PS. Исходное состояние стека определяет корневые AM и PS (rootAM, rootPS).
Создание пары (AM, PS) осуществляется при интерпретации вызова
mapam_ (AMRef *AMRefPtr, PSRef *PSRefPtr ).
При вызове runam_ топология PS, на которую отображается соответствующая АМ, считывается из конфигурационного файла Предиктора (Predictor.par). АМ нужна Предиктору только для того, чтобы установить текущую PS. Характеристики и топология исходной PS выбираются из трассы (по вызовам crtps_ и psview_ - нужны AMRef, PSRef).
Вызов getamr_ имеет параметр:
IndexArray - массив, i-й элемент которого содержит значение индекса опрашиваемого элемента (т.е. абстрактной машины) по измерению i+1. Для Предиктора важно только лишь то, что создается новая АМ, которая в дальнейшем отображается на вновь созданную PS.
Алгоритм моделирования: на основе информации, считанной из файла параметров, создается объект класса VM (конструктор VM::VM(long ARank, long* ASizeArray, int AMType, double ATStart, double ATByte)). Ссылка на этот объект, а также возвращаемый функцией параметр PSRef, запоминаются в структуре описания МПС.
Функция:
|
crtamv_ |
- создание представления абстрактной машины. |
Алгоритм моделирования: на основе записанных в трассировке параметров Rank и SizeArray[] создается объект класса AMView (конструктор AMView::AMView(long ARank, long* ASizeArray)). Ссылка на этот объект, а также входной параметр AMRef и возвращаемый функцией параметр AMViewRef, запоминаются в новом элементе массива представлений абстрактных машин.
Функция:
|
crtda_ |
- создание распределенного массива. |
Алгоритм моделирования: на основе записанных в трассировке параметров Rank, SizeArray[] и TypeSize создается объект класса DArray (конструктор DArray::DArray(long ARank, long* ASizeArray, long ATypeSize)). Ссылка на этот объект, а также возвращаемый функцией параметр ArrayHandlePtr, запоминаются в новом элементе массива распределенных массивов.
Функция:
|
crtrg_ |
- создание редукционной группы. |
Алгоритм моделирования: создается объект класса RedGroup (конструктор RedGroup::RedGroup(VM* AvmPtr)). В качестве параметра AvmPtr передается ссылки на объект класса VM, созданный в процессе моделирования функции crtps_. Ссылка на созданный объект, а также возвращаемый функцией параметр RedGroupRef, запоминаются в новом элементе массива редукционных групп.
Функция:
|
crtred_ |
- cоздание редукционной переменной. |
Алгоритм моделирования: создается объект класса RedVar (конструктор RedVar::RedVar(long ARedElmSize, long ARedArrLength, long ALocElmSize)). Параметры ARedArrLength и ALocElmSize берутся из параметров вызова функции, а параметр ARedElmSize вычисляется исходя из параметра вызова RedArrayType по следующей таблице:
|
RedArrayType |
Тип языка C |
ARedElmSize |
|
1 (rt_INT) |
int |
sizeof(int) |
|
2 (rt_LONG) |
long |
sizeof(long) |
|
3 (rt_FLOAT) |
float |
sizeof(float) |
|
4 (rt_DOUBLE) |
double |
sizeof(double) |
Ссылка на созданный объект, а также возвращаемый функцией параметр RedRef, запоминаются в новом элементе массива редукционных переменных.
Функция:
|
crtshg_ |
- cоздание группы границ. |
Алгоритм моделирования: создается объект класса BoundGroup (конструктор BoundGroup::BoundGroup()). Ссылка на созданный объект, а также возвращаемый функцией параметр ShadowGroupRef, запоминаются в новом элементе массива групп границ.
Функция:
|
delamv_ |
- уничтожение представления абстрактной машины. |
Алгоритм моделирования: в массиве представлений абстрактных машин ищется элемент с ключом AMViewHandlePtr (AMViewRef). Если элемент найден, уничтожается созданный в процессе моделирования функции crtamv_ объект класса AMView, после чего данный элемент удаляется из массива.
Функция:
|
delda_ |
- уничтожение распределенного массива. |
Алгоритм моделирования: в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr. Если элемент найден, уничтожается созданный в процессе моделирования функции crtda_ объект класса DArray, после чего данный элемент удаляется из массива.
Функции:
|
delred_ |
- уничтожение редукционной переменной; |
|
delrg_ |
- уничтожение редукционной группы. |
Алгоритм моделирования: в массиве редукционных переменных (редукционных групп) ищется элемент с ключом RedRef (RedGroupRef). Если элемент найден, уничтожается созданный в процессе моделирования объект класса RedVar (RedGroup), после чего элемент удаляется из массива.
Функция:
|
delshg_ |
- уничтожение группы границ. |
Алгоритм моделирования: в массиве групп границ ищется элемент с ключом ShadowGroupRef. Если элемент найден, уничтожается созданный в процессе моделирования объект класса BoundGroup, после чего элемент удаляется из массива.
3.6 Функции распределения ресурсов и данных
В данную группу входят функции, осуществляющие начальное распределение и перераспределение ресурсов и данных.
Функция:
|
distr_ |
- |
задание отображения представления абстрактной машины на многопроцессорную систему (распределение ресурсов). |
Алгоритм моделирования: в массиве представлений абстрактных машин ищется элемент с ключом AMViewRef. Если элемент найден, вызывается метод AMView::DisAM(VM *AVM_Dis, long AParamCount, long* AAxisArray, long* ADistrParamArray). В качестве параметра AVM_Dis передается ссылки на объект класса VM, созданный в процессе моделирования функции crtps_, остальные параметры соответствуют параметрам вызова функции.
Функция:
|
align_ |
- задание расположения (выравнивание) pаспределенного массива. |
Алгоритм моделирования: в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr. В зависимости от типа образца выравнивания (AMView или DisArray), в массиве представлений абстрактных машин или в массиве распределенных массивов ищется элемент с ключом PatternRef. Для объекта класса DArray из найденной в массиве распределенных массивов записи с ключом ArrayHandlePtr вызывается метод DArray::AlnDA(AMView*{DArray*} APattern, long* AAxisArray, long* ACoeffArray, long* AConstArray). В качестве первого параметра передается ссылка на объект типа AMView или DArray, в зависимости от типа образца, соответствующий ключу PatternRef. Остальные параметры извлекаются из параметров вызова функции. Кроме этого, запоминается тип образца выравнивания. При моделировании игнорируется пересылка данных в процессе выравнивания распределенного массива.
Функция:
|
redis_ |
- |
изменение отображения представления абстрактной машины на многопроцессорную систему (перераспределение ресурсов). |
Алгоритм моделирования: в массиве представлений абстрактных машин ищется элемент с ключом AMViewRef. Для объекта класса AMView из найденной в массиве представлений абстрактных машин записи вызывается метод AMView::RDisAM(long AParamCount, long* AAxisArray, long* ADistrParamArray, long ANewSign). Параметры извлекаются из параметров вызова функции.
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения redis_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора. Время, возвращенное методом AMView::RDisAM(…), прибавляется к Execution_time и к Redistribution каждого процессора. После этого работа функции считается завершенной.
Функция:
|
realn_ |
- изменение расположения распределенного массива. |
Алгоритм моделирования: в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr. В зависимости от типа нового образца выравнивания (AMView или DisArray), в массиве представлений абстрактных машин или в массиве распределенных массивов ищется элемент с ключом PatternRef. Для объекта класса DArray из найденной в массиве распределенных массивов записи с ключом ArrayHandlePtr вызывается метод DArray::RAlnDA(AMView*{DArray*} APattern, long* AAxisArray, long* ACoeffArray, long* AConstArray, long ANewSign). В качестве первого параметра передается ссылка на объект типа AMView или DArray, в зависимости от типа образца, соответствующий ключу PatternRef. Остальные параметры извлекаются из параметров вызова функции. Запоминается тип нового образца выравнивания. Если параметр NewSign равен 1, ищется вложенный вызов функции crtda_ и ключ массива заменяется новым значением, полученным как выходной параметр ArrayHandlePtr функции crtda_. Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения realn_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора. Время, возвращенное методом DArray::RAlnDA(…), прибавляется к Execution_time и к Redistribution каждого процессора. После этого работа функции считается завершенной.
3.7 Функции инициализации коллективных операций
В данную группу входят функции, осуществляющие вставку редукционной переменной в редукционную группу и вставку границ распределенного массива в группу границ.
Функция:
|
insred_ |
- включение редукционной переменной в редукционную группу. |
Алгоритм моделирования: в массиве редукционных переменных ищется элемент с ключом RedRef и соответствующий ему объект класса RedVar; в массиве редукционных групп ищется элемент с ключом RedGroupRef и соответствующий ему объект класса RedGroup. Вызывается метод RedGroup::AddRV(RedVar* ARedVar) для найденного объекта класса RedGroup с найденным объектом класса RedVar в качестве параметра.
Функция:
|
inssh_ |
- включение границы распределенного массива в группу границ. |
Алгоритм моделирования: в массиве групп границ ищется элемент с ключом ShadowGroupRef и соответствующий ему объект класса BoundGroup; в массиве распределенных массивов ищется элемент с ключом ArrayHandlePtr и соответствующий ему объект класса DArray. Вызывается метод BoundGroup::AddBound(DArray* ADArray, long* ALeftBSizeArray, long* ARightBSizeArray, long ACornerSign) для найденного объекта класса BoundGroup. В качестве первого параметра передается ссылка на найденный объект класса DArray; параметру ALeftBSizeArray соответствует входной параметр LowShdWidthArray функции inssh_, параметру ARightBSizeArray – параметр HiShdWidthArray, параметру ACornerSign – параметр FullShdSign.
Функция:
|
Across |
- привязывание границ распределенного массива к текущему параллельному циклу |
Алгоритм моделирования: К информации о текущем параллельном цикле, на которую указывает ParLoopInfo, приписываются ссылки на границы, заданные параметрами OldShadowGroupRef и NewShadowGroupRef. Также присваивается признак (ParLoopInfo.across) того, что этот цикл надо выполнить с помощью конвейерной обработки.
Алгоритм моделирования времени отличается от основного. Счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения across. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора.
3.8 Функции выполнения коллективных операций
В данную группу входят функции, осуществляющие выполнение коллективных операций.
Функция:
|
arrcpy_ |
- копирование распределенных массивов. |
Алгоритм моделирования: в массиве распределенных массивов ищутся элементы с ключами FromArrayHandlePtr и ToArrayHandlePtr. Выполняется функция ArrayCopy(DArray* AFromArray, long* AFromInitIndexArray, long* AFromLastIndexArray, long* AFromStepArray, DArray* AToArray, long* AToInitIndexArray, long* AToLastIndexArray, long* AToStepArray, long ACopyRegim). В качестве параметров ей передаются указатели на объекты класса DArray из найденных записей и параметры FromInitIndexArray[], FromLastIndexArray[], FromStepArray[], ToInitIndexArray[], ToLastIndexArray[], ToStepArray[], CopyRegim из вызова функции arrcpy_.
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения arrcpy_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора. Время, возвращенное функцией ArrayCopy(…), прибавляется к Execution_time и к Remote_access каждого процессора. После этого работа функции считается завершенной.
Функция:
|
strtrd_ |
- запуск редукционной группы. |
Алгоритм моделирования: в массиве редукционных групп ищется элемент с ключом RedGroupRef. Для объекта класса RedGroup из найденного элемента вызывается метод RedGroup::StartR(DArray* APattern, long ALoopRank, long* AAxisArray). Параметры APattern, ALoopRank и AAxisArray берутся из структуры, которая была заполнена при последнем вызове функции mappl_ и соответствуют последнему отображенному параллельному циклу. Создается элемент с ключом RedGroupRef в массиве стартовавших редукций. В этом элементе сохраняется время начала редукции, равное максимальному из значений счетчиков процессоров на момент вызова функции strtrd_ и время окончания редукции, равное сумме времени начала редукции и времени, возвращенного методом RedGroup::StartR(…). В случае, если образцом для отображения параллельного цикла послужил не распределенный массив, а представление абстрактной машины, фиксируется ошибка и моделирование прекращается.
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения strtrd_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора.
Функция:
|
strtsh_ |
- запуск обмена границами заданной группы. |
Алгоритм моделирования: в массиве групп границ ищется элемент с ключом ShadowGroupRef. Для объекта класса BoundGroup из найденного элемента вызывается метод BoundGroup::StartB(). Создается элемент с ключом ShadowGroupRef в массиве стартовавших обменов границами. В этом элементе сохраняется время начала обменов, равное максимальному из значений счетчиков процессоров на момент вызова функции strtsh_ и время окончания обменов, равное сумме времени начала обменов и времени, возвращенного методом BoundGroup::StartB().
Алгоритм моделирования времени отличается от основного. Сначала счетчики времени всех процессоров приводятся к одному значению, равному максимальному из значений счетчиков на момент начала выполнения strtsh_. Время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Synchronization данного процессора.
Функция:
|
waitrd_ |
- ожидание завершения редукции. |
Алгоритм моделирования: в массиве стартовавших редукций ищется элемент с ключом RedGroupRef. По окончании моделирования данный элемент удаляется из массива.
Алгоритм моделирования времени отличается от основного. Для каждого процессора сравнивается текущее значение счетчика времени и время окончания редукции, зафиксированное в процессе моделирования функции strtrd_, при этом разница времен прибавляется к Reduction_overlap. Если значение счетчика времени процессора меньше, чем время окончания редукции, то значение счетчика приводится к времени окончания редукции, при этом время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Reduction_wait данного процессора. После этого работа функции считается завершенной.
Функция:
|
waitsh_ |
- ожидание завершения обмена границами заданной группы. |
Алгоритм моделирования: в массиве стартовавших обменов границами ищется элемент с ключом ShadowGroupRef. По окончании моделирования данный элемент удаляется из массива.
Алгоритм моделирования времени отличается от основного. Для каждого процессора сравнивается текущее значение счетчика времени и время окончания обменов, зафиксированное в процессе моделирования функции strtsh_, при этом разница времен прибавляется к Shadow_overlap. Если значение счетчика времени процессора меньше, чем время окончания обменов, то значение счетчика приводится к времени окончания обменов, при этом время, которое было добавлено к счетчику, прибавляется к Execution_Time и к Wait_shadow данного процессора. После этого работа функции считается завершенной.
3.9 Функции организации параллельного цикла
В данную группу входят функции, осуществляющие инициализацию параллельного цикла, распределение его витков между процессорами и его выполнение.
Функция:
|
crtpl_ |
- создание параллельного цикла. |
Алгоритм моделирования: в структуру, описывающую параллельный цикл, записывается параметр Rank – размерность параллельного цикла.
Функция:
|
mappl_ |
- отображение параллельного цикла. |
Алгоритм моделирования: создается объект класса ParLoop (конструктор ParLoop:: ParLoop (long ARank)). Метод ParLoop::MapPL(AMView*{DArray*} APattern, long* AAxisArray, long* ACoeffArray, long* AconstArray, long* AInInitIndex, long* AInLastIndex, long* AInLoopStep) моделирует распределение витков параллельного цикла по процессорам. Далее, для каждого процессора строится объект, соответствующий блоку витков цикла, отображенному на данный процессор (конструктор LoopBlock::LoopBlock(ParLoop *pl, long ProcLI)). Кроме того, в структуре, описывающей параллельный цикл, запоминается ключ образца отображения (PatternRef) и его тип.
Функция:
|
dopl_ |
- опрос необходимости продолжения выполнения параллельного цикла. |
Алгоритм моделирования: Алгоритм моделирования времени отличается от основного и существует два случая в зависимости от признака ParLoopInfo.across.
1. ParLoopInfo.across == true
Если значение DoPL при возврате ret_dopl_ равно 1, то производится обмен старыми значениями элементов массива. В зависимости от знака шага вычисления параллельного цикла берется или левая или правая граница массива.
Если значение DoPL при возврате ret_dopl_ равно 0, то производится конвейерная обработка параллельного цикла. Вызывается функция ParLoopInfo.ParLoop_Obj->AcrossCost->Across(…), которая исходя из параметров цикла (его размеров, время выполнения витка цикла, размер границ, обновляемых на каждом витке) делает расчет оптимального количества квантов конвейера. И моделирует выполнение конвейерной обработки параллельного цикла с вычисленным оптимальным количеством квантов. При этом вычисляет и добавляет в текущий интервал время, необходимое для передачи данных, и количество времени, которое потребуется каждому процессору для выполнения своей порции вычислений.
2. ParLoopInfo.across == false.
Вычисляется и запоминается общее количество витков цикла (Nвитков) и количество витков цикла на каждом процессоре (Ni). Для каждого процессора вычисляется величина Тфунк*(Ni/Nвитков) и прибавляется к Execution_time и CPU_time данного процессора. Кроме того, область вычислений процессора сравнивается с областями вычислений других процессоров, вычисляется число процессоров, выполнявших одинаковые витки цикла (Nпроц), потом для каждого процессора, выполнявшего данную часть цикла, вычисляется величина (Тфунк/Ni)*((Nпроц-1)/Nпроц) и прибавляется к Insufficient_parallelism_Par.
Алгоритм моделирования: неизвестные функции моделируются по основному алгоритму. При этом выдается предупреждение о встрече в трассировке неизвестной функции с указанием ее названия.
4 Оценка накладных расходов доступа к удаленным данным
4.1 Основные понятия и термины
Прежде чем переходить к описанию используемых алгоритмов оценки накладных расходов доступа к удаленным данным, необходимо сказать несколько слов о том, как происходит отображение вычислений и данных на распределенную систему. На рис.1 изображена диаграмма распределения массивов по процессорной топологии в DVM модели.
Рис.1.
DVM-модель распределения данных по
процессорам.
Вводится понятие Представление абстрактной машины (в дальнейшем для краткости будем использовать синонимы данного термина – Шаблон или AMView) – специального массива, предназначенного для обеспечения двухступенчатого отображения массивов и вычислений на систему процессоров: сначала они (Darrays) отображаются на AMView, которая затем отображается на систему процессоров (VM). Первое отображение целиком определяется взаимосвязями вычислений и данных, свойственными алгоритму, и не зависит от архитектуры и конфигурации распределенной вычислительной системы. Второе отображение служит для настройки параллельной программы на предоставляемые ей ресурсы конкретной ЭВМ.
При выполнении выравнивания или повторного выравнивания распределенного массива в качестве AMView может также выступать и обычный распределенный массив, уже отображенный на некоторую AMView (косвенное задание отображения).
Задание информации о выравнивании массивов на шаблон осуществляется при помощи вызова функции DArray::AlnDA. Распределение шаблона на систему процессоров производится путем вызова функции AMView::DisAM.
4.2 Оценка обменов при перераспределении массивов
Рассмотрим алгоритм определения накладных расходов при повторном выравнивании массива на шаблон (realign). Данный алгоритм реализуется функцией DArray::RAlnDA, которая возвращает время затрачиваемое на обмены между процессорами при выполнении указанной выше операции. Кроме этого функция изменяет для данного массива информацию о том, на какой шаблон он отображен и по какому правилу, в соответствии с указанными при обращении к функции параметрами. Производится корректировка списков выровненных массивов для соответствующих шаблонов.
Алгоритм начинается с того, что мы проверяем значение входного параметра ANewSign. При его не нулевом значении содержимое вновь выровненного массива будет обновлено, следовательно, нет необходимости пересылать заведомо не нужные элементы, а значит возвращаемое значение в этом случае равно нулю. Если это не так, то алгоритм продолжает свою работу.
Сохраняем информацию о том, как был расположен массив до повторного выравнивания, и при помощи вспомогательной функции DArray::AlnDA определяем информацию о его новом расположении после выполнения данной операции.
Затем, при помощи функции CommCost::Update(DArray *, DArray *), производится изменение массива CommCost::transfer (инициализирован в начале нулями), содержащего информацию о числе байтов пересылаемых между двумя любыми процессорами, основываясь на информации о расположении массива до и после повторного выравнивания, полученной выше.
В конце определяем искомое время по полученному массиву transfer, используя функцию CommCost::GetCost.
Теперь опишем алгоритм, реализуемый функцией Update:
1. На вход поступает информация о распределении массива до и после выполнения операции (назовем ее перераспределением массива) меняющей расположение массива. Вначале проверяем, был ли массив полностью размножен по шаблону до перераспределения (оформление этого признака производится во вспомогательной функции DArray::AlnDA). Пусть это так, иначе переходим к пункту 2. Если множество процессоров (обозначим его М1), на которых были расположены элементы шаблона до перераспределения массива, содержит в себе множество процессоров (обозначим его М2), на которых расположены элементы шаблона после перераспределения, то пересылок нет, следовательно, массив transfer не изменяется и алгоритм заканчивает свою работу. В противном случае для каждого процессора (обозначим его П2) принадлежащего разности множеств М2 и М1 находим ближайший к нему процессор (обозначим его П1) из множества М1 (он лежит на границе прямоугольной секции образованной процессорами принадлежащими множеству М1). Далее для каждой такой пары процессоров выполняем ниже описанные действия. Для процессора П2 находим принадлежащую ему после перераспределения секцию массива, используя конструктор Block::Block(DArray *, long). Секция массива, располагавшаяся на процессоре П1 до выполнения операции, совпадает со всем массивом, т.к. тот был полностью размножен по шаблону. Взяв пересечение этих двух секций, используя operator ^ (Block &, Block &), мы получаем секцию подлежащую пересылке с процессора П1 на процессор П2. Определив число байтов в ней, воспользовавшись функцией Block::GetBlockSize, добавляем его к соответствующему элементу массива transfer. Алгоритм заканчивает свою работу.
Определяем все измерения системы процессоров, по которым размножен или частично размножен массив до перераспределения. Если таких измерений не имеется, то переходим к пункту 3. Для измерений системы процессоров, по которым массив частично размножен, определяем множества значений индексов, при которых на соответствующих процессорах имеются элементы массива до перераспределения. Обходим все процессоры (обозначим текущий как П1) чьи индексы в измерениях, по которым размножен массив, равны нулю, а в тех измерениях, по которым массив частично размножен, равны минимумам из соответствующих полученных множеств.
2. Определяем для этих процессоров секции массива находившиеся на них до перераспределения. Для всех процессоров (обозначим текущий как П2) определяем секции массива, которые расположены на них после перераспределения. Находим пересечение выше описанных секций для текущих процессоров П1 и П2. Для процессора П2 определяем ближайший к нему процессор, секция массива на котором совпадает с секцией на процессоре П1. Индексы этого процессора по всем измерениям системы процессоров совпадают с соответствующими индексами процессора П1 за исключением индексов по измерениям, по которым массив размножен или частично размножен. По этим измерениям индексы берутся наиболее близкими к соответствующим индексам процессора П2 (определяются используя полученные выше множества). Если номер полученного процессора не совпадает с номером П2, то в соответствующий элемент массива transfer добавляем число байтов в найденном выше пересечении. После обработки всех пар процессоров (П1, П2), алгоритм завершает свою работу.
3. Для каждого процессора определяем секцию массива расположенную на нем до перераспределения. Также для каждого процессора определяем секцию массива расположенную на нем после перераспределения. Находим пересечение таких секций, для каждой пары не совпадающих процессоров. Число байтов в пересечении добавляем к элементу массива transfer, соответствующему данной паре процессоров. После обработки всех таких пар процессоров, алгоритм завершает свою работу.
В функции GetCost, для нахождения времени затрачиваемого на обмены между процессорами, используется один из двух алгоритмов – в зависимости от типа распределенной системы процессоров. В случае сети с шинной организацией искомое время определяется по следующей формуле:
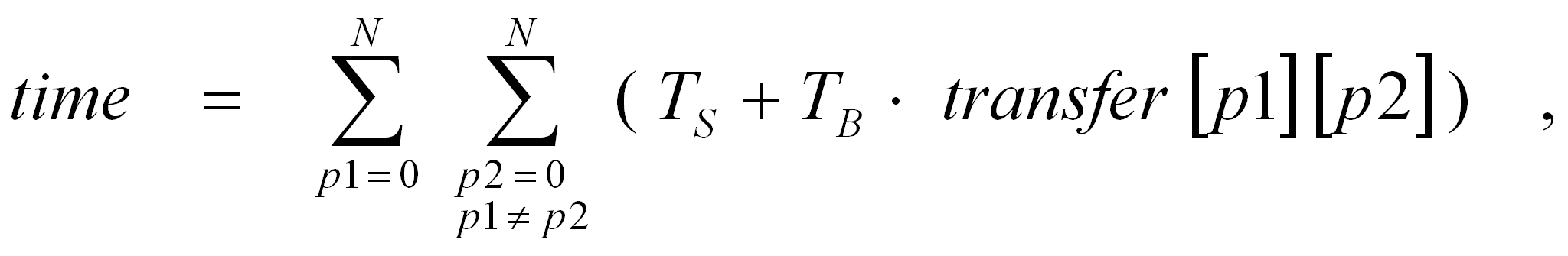
где N – число процессоров, Ts – время старта операции обмена, TB – время пересылки одного байта. Эта формула следует из того, что в сети не может одновременно находится несколько сообщений и, следовательно, общее время равно сумме всех времен обменов между двумя любыми не совпадающими между собой процессорами.
Для транспьютерной решетки общее время в основном зависит от расстояния (кратчайшего пути) между двумя наиболее удаленными друг от друга процессорами, между которыми существуют обмены. Также при оценке этого времени для данного типа системы необходимо учесть возможность конвейеризации сообщений. Исходя из этих замечаний, получаем следующий алгоритм и формулу для определения накладных расходов:
Обходим массив transfer и для всех отличных от нуля элементов определяем при помощи функции VM::GetDistance(long, long) расстояние между соответствующими процессорами. Определяем текущее максимальное расстояние и текущее максимальное число байтов, пересылаемое на данное расстояние. Продолжаем так, пока не обойдем весь массив transfer. В итоге найдем: l – расстояние между двумя наиболее удаленными друг от друга процессорами, между которыми существуют обмены и LB – длину в байтах самого большого сообщения пересылаемого на расстояние l. Если l = 0, то результат равен нулю и алгоритм завершает свою работу. Иначе переходим к следующему пункту.
Если l = 1, то искомое время определяем по формуле:
Если l > 1, то возможна конвейеризация сообщения. Поэтому вначале исследуем на экстремум следующую функцию, описывающую зависимость времени пересылки сообщения размера LB от размера S сообщения пересылаемого за одну фазу конвейера:
Получим, что минимум данной функции достигается при
С учетом того, что размер сообщения пересылаемого за одну фазу конвейера и число фаз – целые числа, мы приходим к следующему выражению:
где S’ = [S] (S’ = 1, если [S] = 0); c Î {0, 1} – признак того, что LB не делится нацело на S’. Для нахождения точного значения определим время по этой же формуле, но в соседних с S’ целочисленных точках. Если они больше, то найденное в точке S’ значение является искомым. Иначе производим поиск в направлении убывания, пока на некотором шаге k не получим значения большего чем на шаге k–1. Тогда искомым временем будет являться значение, полученное на k–1 шаге. Алгоритм завершает свою работу.
В заключение данного параграфа рассмотрим алгоритм нахождения накладных расходов при перераспределении шаблона. Эти расходы возникают в связи с тем, что все распределенные массивы, ранее выровненные по рассматриваемому шаблону с помощью функции DArray::AlnDA (как непосредственно, так и косвенно), будут отображены заново по прежним правилам выравнивания на этот шаблон после того, как он поменяет свое расположение на системе процессоров, следовательно, и они поменяют свое расположение, что приведет к обменам. Данный алгоритм реализуется функцией AMView::RDisAM, которая возвращает время затрачиваемое на выполнение обменов между процессорами при выполнении данной операции. Также функция изменяет для данного шаблона информацию о том, по какому правилу он был отображен в систему процессоров (установленную ранее с помощью функции AMView::DisAM), на информацию о его новом распределении в соответствии с параметрами указанными при обращении к функции.
Алгоритм начинается с того, что мы проверяем значение входного параметра ANewSign. Если он не равен нулю, то это означает, что содержимое всех распределенных массивов, ранее выровненных по рассматриваемому шаблону, будет обновлено, следовательно, нет необходимости пересылать заведомо не нужные элементы, а значит возвращаемое значение в этом случае равно нулю. Если это не так, то алгоритм продолжает свою работу.
Затем, предварительно сохранив информацию о том, как был распределен шаблон до перераспределения, определяем при помощи вспомогательной функции AMView::DisAM информацию о его распределении после выполнения данной операции. Это нужно для того, чтобы знать, как расположены выровненные по данному шаблону массивы до и после перераспределения.
Далее для каждого массива, выровненного по рассматриваемому шаблону, при помощи функции CommCost::Update(DArray *, DArray *), производится изменение массива CommCost::transfer (инициализирован в начале нулями), основываясь на информации о расположении массива до и после повторного выравнивания, полученной выше.
В конце определяем искомое время по полученному массиву transfer, используя функцию CommCost::GetCost.
4.3 Оценка обменов границами распределенных массивов
Рассмотрим алгоритм вычисления времени затрачиваемого на обмен границами заданной группы. Он состоит из двух частей:
Производится включение всех требуемых границ распределенных массивов в заданную группу, используя функцию BoundGroup::AddBound для каждого такого массива. При этом соответствующим образом изменяется массив transfer.
Определяем искомое время по полученному массиву transfer, используя функцию CommCost::GetCost (это происходит при вызове функции BoundGroup::StartB).
Алгоритм, реализуемый функцией CommCost::GetCost, был описан в предыдущем параграфе, поэтому остановимся на алгоритме функции BoundGroup::AddBound:
Если массив полностью размножен, происходит выход из функции без изменения массива transfer (инициализируется нулями при создании группы). Иначе алгоритм продолжает свою работу. Далее проверяется возможность включения границы данного массива в группу при данных параметрах функции. Если это возможно, то при помощи функции DArray::GetMapDim определяем: по каким измерения системы процессоров будет реальный обмен границами (это те измерения, по которым массив не размножен), соответствующие им измерения массива и направления разбиения этих измерений массива. Заносим эту информацию в массив dimInfo (его элементы – объекты класса DimBound). Затем уточняем признак включения в границы “угловых” элементов: он присутствует, если параметр данной функции ACornerSign равен 1 и число измерений системы процессоров, по которым будет происходить обмен границами больше 1. Производится вызов функции CommCost::BoundUpdate с информацией определенной выше в качестве параметров.
В функции BoundUpdate для каждого процессора выполняются описанные ниже действия. Определяем секцию массива находящуюся на данном процессоре. Если на этом процессоре нет элементов массива, то мы переходим к следующему процессору. Иначе для данного процессора определяем требуемые пересылки для правых и левых границ секций массива, расположенных на соседних процессорах по измерениям, содержащимся в массиве dimInfo. Для этого обходим массив dimInfo и определяем для данной секции массива при помощи функции Block::IsLeft (IsRight), есть ли по текущему измерению распределенного массива элементы находящиеся левее (правее) данных. Если есть, то при условии того, что правая (левая) граница по данному измерению задана при обращении к функции AddBound, определяем величину пересылаемой границы и при помощи функции VM::GetSpecLI находим номер соседнего процессора на который пересылается данная граница (используя информацию из массива dimInfo, соответствующую данному измерению массива). Величина пересылаемой границы определяется, как размер в байтах текущей секции, в которой число элементов по текущему измерению массива равно ширине правой (левой) границы по этому измерению. Это значение прибавляется к соответствующему элементу матрицы transfer. Закончив с правыми и левыми границами, переходим к “угловым” элементам, если присутствует признак включения их в границы массива (рассмотрим только для случая, когда “угловые” элементы образуются пересечением реальных границ по двум измерениям, т.е. в массиве dimInfo два элемента). Аналогично описанному выше, только уже по всей совокупности измерений массива хранящихся в dimInfo, определяем для данной секции массива существование элементов, которые являются соседними по данным измерениям для угловых элементов секции по направлениям всех диагоналей в этой совокупности измерений (используя функции IsLeft и IsRight). Если существуют, то при условии, что соответствующие границы по данным измерениям заданны, определяем размер пересылаемой секции “угловых” элементов и при помощи функции VM::GetSpecLI (используется столько раз, сколько измерений в данной совокупности) находим номер соседнего процессора на который пересылается данная граница (используя информацию из массива dimInfo, соответствующую данным измерениям массива). Величина пересылаемой секции определяется, как размер в байтах текущей секции, в которой число элементов по каждому измерению массива из этой совокупности равно ширине соответствующей границы по этому измерению, участвующей в образовании данной секции “угловых” элементов. Это значение прибавляется к соответствующему элементу матрицы transfer. Алгоритм завершает свою работу.
4.4 Оценка обменов при выполнении операций редукции
Алгоритм определения времени затрачиваемого на обмены при выполнении операций редукции реализован в функции RedGroup::StartR, но прежде чем перейти к его описанию покажем, какая предварительная работа производится.
При добавлении очередной редукционной переменой к редукционной группе при помощи функции RedGroup::AddRV производится увеличение счетчика числа пересылаемых при запуске редукционной группы байтов - TotalSize на величину равную размеру в байтах редукционной переменой и дополнительной информации, сопровождающей редукционную операцию (задается для некоторых редукционных операций). Информация же о типе редукционной операции при оценке обменов возникающих при ее выполнении не важна.
Описание функции StartR:
На вход подается информация о том, на какой массив отображен параллельный цикл, в котором выполняются операции редукции из данной редукционной группы; число измерений параллельного цикла; массив содержащий информацию о том, как отображаются измерения цикла на измерения массива. Если массив, на который отображен параллельный цикл, полностью размноженный, то выходим из функции с нулевым временем. Иначе по входной информации, используя функцию DArray::GetMapDim, определяем для каждого измерения цикла измерение системы процессоров, на которое он в итоге отображен, либо то, что оно размножено по всем измерениям системы процессоров (помещаем соответствующий номер измерения или ноль в массив loopAlign). Далее по этой информации определяем искомое время в зависимости от типа распределенной системы.
Если мы имеем сеть с шинной организацией, то основная идея заключается в том, что при сборе информации ненужно пересылать ее вдоль измерений, по которым цикл размножен. Следовательно, мы можем собрать ее только по одной секции образованной процессорами с фиксированными индексами по данным измерениям. Затем рассылаем полученный результат по всем процессорам. Это приводит к следующей формуле:
time = (TS + TB * TotalSize) * (Ni1 * ... * Nik + N – 2) ,
где N – число процессоров, Ts – время старта операции обмена, TB – время пересылки одного байта, Nik – число процессоров по измерению системы процессоров с номером loopAlign[ik], на которых присутствуют витки цикла. Функция возвращает полученное значение.
Если же это транспьютерная решетка, то мы можем в параллель собрать информацию по всем таким секциям, описанным в пункте 2, а затем по ним же разослать результат редукционной операции. При этом время сборки значений и рассылки результата зависит от расстояния между геометрическим центром такой секции и ее наиболее удаленным от центра углом. Поэтому вначале определяем это расстояние (обозначим Distance), используя массив loopAlign и информацию о размере соответствующих измерений системы процессоров. Затем по следующей формуле определяем искомое время:
time = (TS + TB * TotalSize) * (2 * Distance + ConerDistance),
где ConerDistance – расстояние от данных секций до наиболее удаленного углового процессора. Возвращаем полученное значение.
4.5 Оценка обменов при загрузке буферов удаленными элементами массивов
Если выравниванием массивов не удается избавиться от удаленных данных и для доступа к ним нельзя использовать теневые грани, то их буферизация на каждом процессоре осуществляется через отдельный буферный массив. Оценка времени, затрачиваемого на обмены при загрузке этих буферов производится в функции ArrayCopy. Ниже приводится описание алгоритма реализуемого функцией ArrayCopy:
При помощи функции DArray::CheckIndex проверяем входные параметры, задающие размеры секции читаемого и присваиваемого массивов, на не выход за границы этих массивов. Если это так, то алгоритм продолжает свою работу, иначе прекращает свою работу, выдавая при этом сообщение об ошибке.
Далее обрабатываются следующие 3 возможных случая:
Если читаемый массив полностью размножен, то коммуникаций не будет и функция завершает свою работу.
Если читаемый массив не является полностью размноженным, а присваиваемый массив полностью размножен, то используется функцию CommCost::CopyUpdate. Она производит изменение массива transfer (инициализирован нулями в начале функции) исходя из параметров задающих секцию, подлежащую размножению и информации о распределении данного массива.
Если читаемый и присваиваемый массивы не являются полностью размноженными, то запускается цикл по всем процессорам. В цикле для каждого процессора вычисляется блок из читаемого массива, который нужно присвоить элементам присваиваемого массива, находящимся на этом процессоре. Далее вызывается функция CommCost::CopyUpdateDistr и в качестве параметров передаются читаемый массив, вычисленный блок, и номер процессора из цикла. Эта функция вычислит, какие элементы из вычисленного блока не лежат на данном процессоре, и, следовательно, их надо передать и они добавляются в массив transfer (инициализирован нулями в начале функции).
Определяем искомое время по полученному массиву transfer, применив функцию CommCost::GetCost (см. п.3.2.).
В функции CopyUpdate выполняется расчет рассылки локальных блоков, имеющихся на каждом процессоре, всем остальным процессорам в виде следующей последовательности действий:
Запускается цикл по всем процессорам (обозначим переменную цикла П1)
Для процессора П1 вычисляются, какие элементы читаемого массива, из тех которые лежат на этом процессоре, подлежат размножению. Для этого делается пересечение блоков, лежащего на процессоре П1 и блока для размножения.
Если таких элементов нет, то берется следующий процессор П1. Если же такие элементы составляют непустой блок (обозначим bi), то запускается цикл по всем остальным кроме П1 процессорам П2. И для каждого процессора П2 проверяется: а есть ли у него блок bi (путем пересечения локального блока процессора П2 и блока bi). Если пересечение пусто, то значит, таких элементов из блока bi на процессоре П2 нет, а значит, их надо передать от процессора П1 к процессору П2. Соответственно размер блока bi, помноженный на размер одного элемента, добавляется в массив transfer. Когда последний процессор П2 будет обработан, то берется следующий процессор П1
Когда П1 достигнет последнего процессора, функция завершает свою работу.
В функции CopyUpdateDistr выполняется расчет пересылок частей читаемого блока, необходимых для присваивания части локального блока этого процессора П1, в виде следующей последовательности действий:
Запускается цикл по всем остальным кроме П1 процессорам П2. И для каждого процессора П2 проверяется: а есть ли у него какая-нибудь часть читаемого блока, необходимая для присваивания части локального блока процессора П1 (путем пересечения локального блока процессора П2 и блока необходимого для присваивания). Если пересечение не пусто, то, значит, есть такая часть, и ее надо передать от процессора П2 к П1. Соответственно размер этой части, помноженный на размер одного элемента, добавляется в массив transfer.
Когда последний процессор П2 будет обработан, то функция завершает свою работу.
Для более эффективного выполнения параллельного цикла с зависимостями по данным используется конвейерная обработка. Для нее производится расчет оптимального количества квантов функцией CommCost::Across. При этом возможен приближенный расчет (full_mode = 0) или переборная схема, общим объемом не более 1000 вариантов (full_mode = 1). Это управляется переменной full_mode в файле CommCost.cpp.
Функция CommCost::Across работает по следующей схеме.
Ей передаются через параметры:
время работы последовательного цикла,
количество витков,
информация о размерах локальных блоков каждого процессора
размер типа элемента массива, границы которого будут обновляться на каждом витке.
Исходя из размеров локальных блоков каждого процессора, вычисляется конфигурация конвейера, возможно несколько конвейеров работающих параллельно и не мешающих друг другу.
Затем производится расчет оптимального количества квантов по приближенной схеме.
Приближенная схема
Пусть конвейеризируемое измерение параллельного цикла имеет длину M и отображено на линейку из P процессоров.
Пусть также:
|
N |
- |
размер квантуемого измерения цикла; |
|
Q |
- |
число квантов (порций), на которое разбито квантуемое измерение; |
|
Tc |
- |
время выполнения одного витка цикла; |
|
Tm |
- |
среднее время передачи одной обрабатываемой в цикле точки при межпроцессорных обменах; |
|
W |
- |
ширина границы для конвейеризируемого измерения цикла. |
Тогда время выполнения программой пользователя порции витков при конвейеризации схемы ACROSS есть
![]() (1).
(1).
Полное (с учётом межпроцессорных обменов) время выполнения порции витков в общем случае равно
Tirecv + Twrecv + Tp + Twsend + Tisend ,
где:
|
Tirecv |
- |
время инициализации приёма от ожидаемого процессора порции границ, необходимой для выполнения следующей порции витков; |
|
Twrecv |
- |
время ожидания завершения приёма от ожидаемого процессора порции границ, необходимой для выполнения текущей порции витков; |
|
Twsend |
- |
время ожидания завершения передачи ожидающему процессору порции границ, полученной после выполнения предыдущей порции витков; |
|
Tisend |
- |
время инициализации передачи ожидающему процессору порции границ, полученной после выполнения текущей порции витков. |
Время выполнения схемы ACROSS определяется временем работы последнего в линейке процессора и равно
Ta =
|
Tirecv |
+ |
T1,wrecv |
+ |
Tp |
+ |
0 |
+ |
0 |
+ |
|
Tirecv |
+ |
Twrecv |
+ |
Tp |
+ |
Twsend,p |
+ |
Tisend,p |
+ |
|
…….. |
…… |
……… |
…… |
… |
…… |
……… |
…… |
……… |
…… |
|
Tirecv |
+ |
Twrecv |
+ |
Tp |
+ |
Twsend,p |
+ |
Tisend,p |
+ |
|
0 |
+ |
Twrecv |
+ |
Tp |
+ |
Twsend,p |
+ |
Tisend,p |
|
Всего Q строк-слагаемых.
Здесь:
|
T1,wrecv |
- |
время ожидания завершения приёма последним процессором первой порции границ; |
|
Twsend,p |
- |
время ожидания завершения передачи последним процессором порции границ, полученной после выполнения предыдущей порции витков; |
|
Tisend,p |
- |
время инициализации передачи последним процессором порции границ, полученной после выполнения текущей порции витков. |
Реальную передачу порций границ последний процессор линейки не ведёт. Поэтому времена Twsend,p и Tisend,p малы, и, пренебрегая ими, время выполнения схемы ACROSS можно записать как
![]() (2).
(2).
Время T1,wrecv может быть представлено в виде
![]() (3).
(3).
Подставляя (3) в (2) и заменяя Tp по формуле (1), получим
![]() (4),
(4),
где:
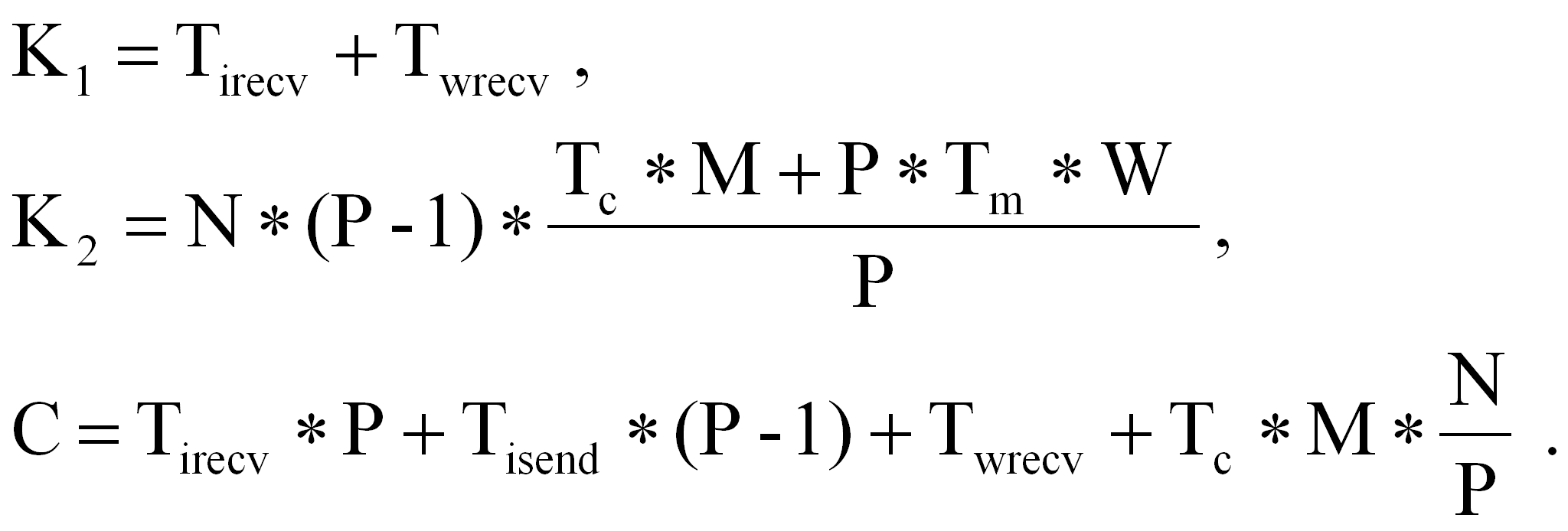
При условии независимости K1, K2 и C от Q минимум времени выполнения схемы ACROSS Ta достигается при
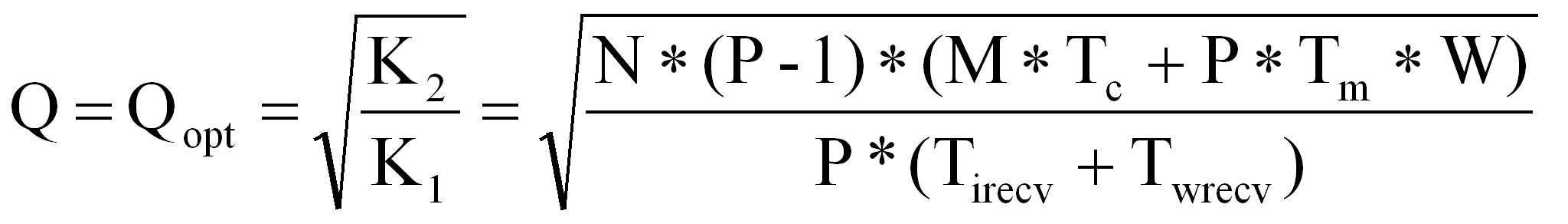 (5).
(5).
Условие независимости K1, K2 и C от Q, при котором была получена формула (5), эквивалентно, очевидно, независимости от Q времени Twrecv. Время Twrecv является константой лишь в том случае, если порция границ, необходимая для выполнения следующей порции витков, успевает поступить от ожидаемого процессора за время выполнения текущей порции. Такой конвейер не вызывает задержек при обменах порциями границ.
В общем случае время Twrecv определяется выражением
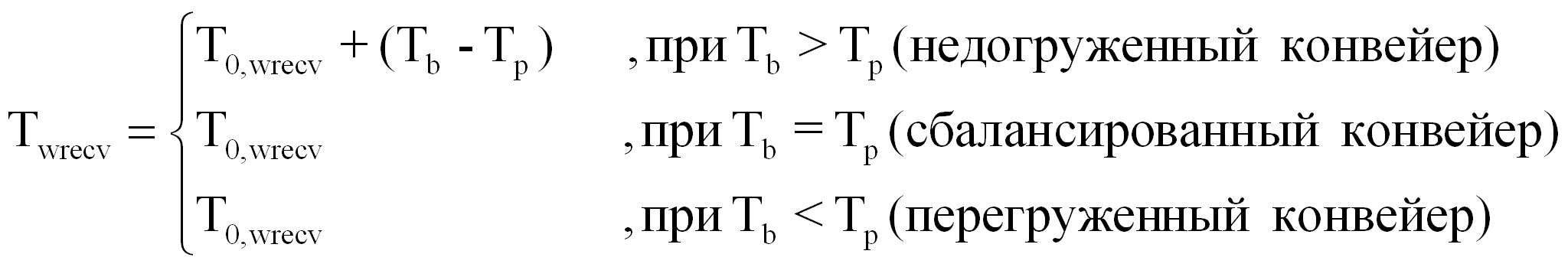 (6)
(6)
Здесь:
|
T0,wrecv |
- |
время ожидания завершения приёма порции границ, уже поступившей от ожидаемого процессора; |
|
Tb |
- |
время передачи порции границ. |
Очевидно,
![]() (7).
(7).
Подставляя (7) и Tp из (1) в (6), имеем
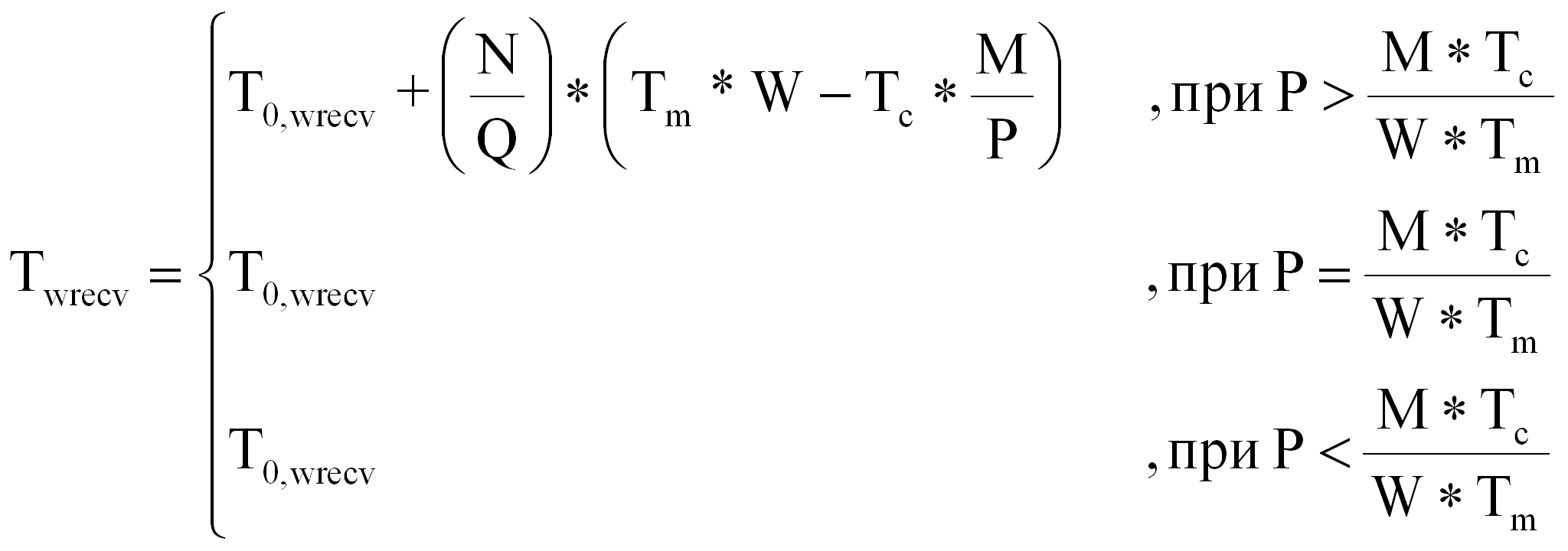 (8)
(8)
Подставляя в (4)
Twrecv
для недогруженного
конвейера
(![]() ),
),
получаем
![]() (9),
(9),
где:
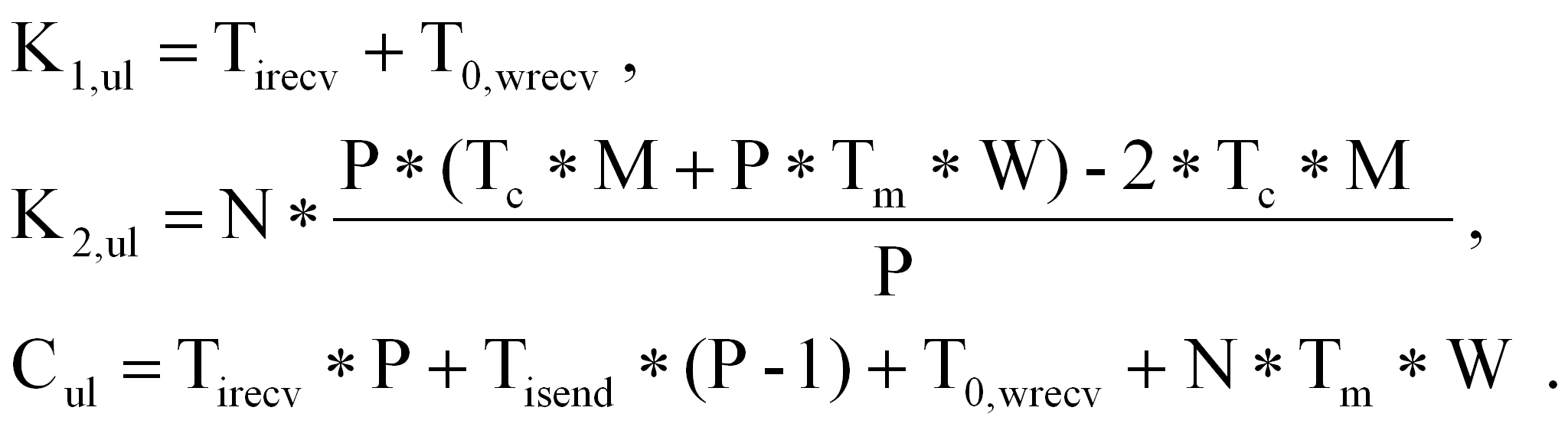
Минимум времени выполнения схемы ACROSS для недогруженного конвейера достигается при
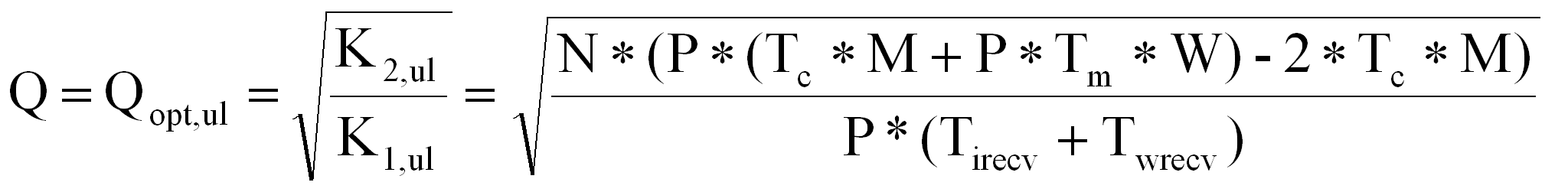 (10).
(10).
Следует подчеркнуть, что при заданных объёмах обрабатываемых
данных (M, N) наименьшее время выполнения цикла ACROSS достигается на
сбалансированном конвейере (при
![]() ),
т.е. в точке перехода от перегруженного конвейера к недогруженному.
),
т.е. в точке перехода от перегруженного конвейера к недогруженному.
Такая схема соответствует одномерному конвейеру, и для него находит наилучший шаг. Но система DVM использует эту схему и в многомерных конвейерах. И в этом случае она оправдывает свое название приближенной схемы.
Расчет шагов многомерного конвейера.
Сначала система поддержки вычисляет, какие измерения можно использовать как конвейеризуемые, а какие как квантуемые. Если конвейеризируемое измерение цикла отображено в измерение процессорной системы единичного размера, то оно исключается из числа конвейеризируемых, и, следовательно, может быть использовано в качестве квантуемого
При этом если не найдет ни одного конвейеризуемого измерения или ни одного квантуемого – то система DVM выполнит цикл без использования конвейера.
Если найдутся необходимые измерения, то система вычисляет произведения всех конвейеризуемых измерений и обозначает за M, а произведение всех квантуемых за N. Ширину границы W для конвейеризируемого измерения цикла, фигурирующую в формулах (5) и (10), рассматривает как суммарный объём всех входящих в группу теневых параллелепипедов (совокупность теневых элементов, по которым идет обмен данными между процессорами), делённый на размер квантуемого измерения цикла.
Вновь вычисленные значения M, N, W подставляются в формулу (10), и система получает оптимальное количество квантов. При распределении общего числа квантов по квантуемым измерениям приоритет отдаётся внешним измерениям цикла: число квантов для самого внешнего измерения полагается равным его размеру; далее общее число квантов делится на этот размер, а остаток аналогично распределяется по наиболее внутренним измерениям.
Далее если указан режим full_mode = 1, то запускается переборная схема, которая пытается улучшить время выполнения всего конвейера, выданное по приближенной схеме.
Переборная схема
Вводится такая сетка перебора и такие ее шаги по каждому из измерений, чтобы суммарный объем вариантов был не более 1000. Для каждого варианта выбора шагов конвейера моделируется выполнения параллельного цикла. Вызывается функция calculate, которая моделирует переход от одного блока к другому (сначала по одному измерению, потом по другому, потом по третьему и т.д.). Размер каждого блока по любому из измерений не превышает соответствующий шаг конвейера. Для каждого такого блока ведется запись, когда закончится вычисляться, и, значит, новые значения этого блока можно передать следующему процессору. Для экономии ресурсов на каждом процессоре ведется запись таких временных отметок только для не более 4 блоков вдоль каждого измерения. Это объясняется тем, что центральные блоки не надо передавать другим процессорам. А времена крайних блоков можно спрогнозировать (линейная экстраполяция) по первым 3 блокам (точнее по первым 2 из середины, так как самый первый может быть меньше срединных)
Также в случае, если глобальная переменная (add = 1), эта функция добавляет информацию о временах работы каждого процессора и о том, сколько заняли коммуникации, в текущий интервал.
Таким образом, при add = 0 производится поиск оптимальных шагов конвейера без добавления времен в интервал.
В конце устанавливается add = 1 и запускается функция calculate с наилучшими шагами (или по приближенной схеме, или еще более улучшенные по переборной схеме), чтобы добавить оптимальные характеристики в интервал. После выполнения этого функция Across заканчивает свое выполнение.
5. Поиск оптимальной конфигурации процессоров
Одной из важных функций предиктора является поиск оптимальной конфигурации и задается он переменной search из файла параметров (predictor.par). Оценочная функция задается в Interval::GetEffectiveParameter() и имеет тип double. При поиске ищется конфигурация процессоров, на которой достигается локальный минимум оценочной функции.
Глобальный минимум – можно найти перебором всех вариантов кроме заведомо худших. И для этого есть соответствующий режим поиска. Однако реализация поиска глобального минимума неэффективна.
Поэтому цель поиска будем считать локальный минимум. При этом важно понимать по каким правилам он локальный и поиск вести таким образом чтобы локальный минимум оказался был ближе к глобальному. Для этого надо будет ввести дополнительные правила на границы сокращения проблемной области.
В качестве оценочной функции можно использовать эффективность программы и искать максимум для нее (т.е. взять за оценочную функцию 1 - эффективность). Однако заведомо известно, что он достигается на одном процессоре, поэтому надо из проблемной области исключить конфигурацию одного процессора.
На некоторых программах эффективность монотонно падает и для них не особо интересно искать оптимальную конфигурацию.
За оценочную функцию можно взять время выполнения программы (именно так и реализовано в текущей версии предиктора)
Проблемная область поиска представлена всевозможными конфигурациями процессоров из заданного кластера (заданного в predictor.par). Но поиск среди всех конфигураций требует много времени, поэтому вводится разные алгоритмы сокращения вариантов перебора.
Основа принципа таких сокращения состоит в зависимости основных продолжительных компонент программы от размерностей процессорной решетки. В этом плане основные компоненты программы – это циклы. Циклы распределяются по данным, а данные распределяются по процессорам. Поэтому в том насколько эффективно будут распределятся данные и зависит время выполнения программы. В качестве исследуемого распределения берется массив максимальных размерностей.
Первое сокращение (априорное) проблемной области состоит в том, что некоторые конфигурации содержат процессоры, на которые не попадают элементы массивов данных и, как следствие, такая конфигурация проигрывает варианту без этих процессоров. Варианты получившиеся после первого сокращения будем называть not_bad.
Для оставшихся вариантов (вариант представлен в виде vector <long>) можно оценить насколько эффективно на них распределились данные функцией CheckEuristik(vector <long>). Эта функция возвращает отношение количества элементов на последнем процессоре к максимальному количеству элементов на каком-либо процессоре. В случае, когда на какой-то процессор не попадают данные, эта функция равна нулю (что позволяет отличить not_bad варианты от bad).
Процедура поиска состоит из поиска среди вариантов с одной эвристикой, сокращении проблемной области в соответствии с текущей оптимальной конфигурацией и переход к вариантам со следующим значением эвристики.
Поиск среди вариантов одинаковой эвристики проходит путем деления пополам.
Сначала находится максимальное из всех вариантов значение эвристики (обозначим его Е). Далее строится вектор значений количества процессоров всех вариантов с эвристикой равной E. Из этого вектора выбирается середина (с округлением вниз). Значение середины обозначим P. И производится перебор вариантов с P процессорами и эвристикой E.
Методы сокращения проблемной области.
На каждом шаге (рассмотрение вариантов с P процессорами и эвристикой E) из проблемной области выкидываются варианты с P процессорами (и уже любой эвристикой).
Основное сокращение проблемной области происходит, когда на очередном шаге (с P процессорами) нет улучшения текущего оптимума (с OP процессорами). Тогда в зависимости от значений P и OP (больше или меньше) происходит исключение из проблемной области вариантов (с большим или меньшим, чем P количеством процессоров соответственно). Этим методом никогда не обрезается область процессоров с количеством процессоров ближайших соседей OP, т.е. ±1 процессор только по одному измерению.
Однако область ближайших соседей может быть обрезана на предыдущих значениях текущего оптимума. Это привносит некоторую степень риска, и есть вероятность, что найденный таким образом локальный минимум отличается от локального минимума по всем измерениям. Этого риска можно и избежать, если хранить историю удаленных вариантов и возвращать их в рассмотрение в случае необходимости. Но пока это не было необходимо, потому что эвристический локальный минимум всегда совпадал с глобальным.
Важно заметить, что область ближайших соседей бывает разных размеров в зависимости от текущей оптимальной конфигурации процессоров. Например, для N*N она будет равна 2*N процессоров, а для 1*N2 она будет 2* N2. Это существенно влияет на количество перебираемых вариантов.
Для улучшения поиска в области ближайших соседей сделан следующий способ сокращения. Он основан на классификации уже перебранных вариантов. Эти варианты группируются в классы, куда входят конфигурации, отличающиеся между собой только значением одного измерения процессоров. Таким образом 1 перебранный вариант попадает сразу в несколько (равных рангу процессорной решетки) классов. Внутри этих классов оценочная функция (время выполнения или эффективность) ведут себя более закономерно, и имеют, как правило, малое число локальных минимумов. Таким образом, найдя в этом классе наилучший вариант (из тех что уже рассмотрели), можно получить для него верхнюю грань по числу процессоров (вариант с наименьшим числом процессоров среди вариантов с количеством процессоров больше числа процессоров наилучшего варианта) и нижнюю грань (наибольший среди меньших лучшего) в виде варианта из этого класса (чья конфигурация тоже уже рассмотрена). Далее можно удалить из последующего рассмотрения все варианты, которые бы попали в этот класс и не попавшие в интервал между нижней и верней гранью.
Этот способ позволяет сильно разредить область ближайших соседей, но он и отдаляет локальный минимум от глобального. Поэтому для этого был введен порог в 0.25 % от текущего лучшего значения оценочной функции. Т.е. если одна из граней (верхняя или нижняя) уступает лучшему варианту не более 0.25 %, то эту грань отодвигают до тех пор пока, варианты обеих граней будут проигрывать текущему лучшему более 0.25 %. Значение в 0.25% было получено экспериментально, чтобы приблизить локальный минимум совпал с глобальным на программе SOR (1000). При необходимости его можно подкорректировать или отдать для настройки пользователю.
Заметим что этот способ разрежает не только область ближайших соседей, но и всю остальную.
В алгоритме поиска заложено, что из множества вариантов с одинаковой эвристикой в случае улучшения текущего оптимума берется как раз одна из границ ближайших соседей с тем, чтобы быстрее отбросить ненужные варианты или, наоборот, быстрее приблизиться к оптимуму. Таким образом проблемная область сокращается в два раза за 1 точку рассмотрения очередного шага в случае неудачи (когда оптимум остается прежним), или за два шага в случае улучшения текущего оптимума (первый - собственно улучшение, второй - одна из границ соседей оптимума, после которой движение идет либо в одну, либо в другую сторону, а ненужная сторона удаляется из проблемной области). Однако такое быстрое сокращение не работает в области ближайших соседей. Там работает механизм отсечения по классам вариантов.
Из алгоритма видно что эвристика используется для выбора вариантов на каждом шаге с последующим переходом к более низким ее значениям. Т.о. эвристика задает некую сетку более или менее равномерную. На первых шагах она часто большая (когда много делителей у максимальной размерности массива), на последующих, как правило, малая.
В предикторе существует несколько режимов поиска оптимальной конфигурации процессоров. Они задаются параметром search из файла параметров predictor.par.
Значение°0 отключает поиск.
Значение°1 говорит о том, что будет использоваться описанный выше эвристический поиск в несколько шагов. Помимо нахождения оптимума в лог файл выдается информация о количестве перебранных вариантов, количество not_bad и общее количество возможных конфигураций. Найденный этим способом с некоторой натяжкой локальный минимум зачастую совпадает с глобальным.
Значение°2 (не рекомендовано) использует перебор not_bad вариантов (с ненулевой эвристикой). Он весьма продолжителен, и его следует использовать только в случае проверки правильности эвристического поиска (т.е. для нахождения глобального минимума оценочной функции и сравнения его с локальным минимумом эвристического поиска). Этот поиск идет в сторону увеличения количества процессоров, т.е. после некоторой величины становится ясно, что текущий оптимум не улучшится.
Значение°3 (крайне не рекомендовано) задает перебор всех вариантов, т.е. без использование эвристики вообще. Его следует использовать только для проверки того, что правильный оптимум не был отсечен при выборе эвристики. Такой случай невозможен, когда в программе распределен один массив, а другие на него выравнивались.
Значение°5 (не рекомендовано) запускает режим сравнения поисков типа 1 и 2. Можно сравнивать как время нахождение оптимума, так и запускать такой поиск на определенное время. Таким образом за это время может проработать эвристический поиск и пройдет значительную долю перебор not_bad вариантов. Однако такой режим носит скорее экспериментальный характер и служит для определения слабых мест в эвристическом поиске с последующей их доработкой.
Для рядового пользователя следует использовать режим 0 (когда поиск не требуется) и 1 (чтобы получить оптимум и прикинуть масштаб поисков всех режимов).
Для запуска предиктора пользователь должен указать в файле параметров отношение производительностей процессоров целевой и инструментальной машины. Поскольку производительность процессора измеряется в количествах определенных операций за единицу времени, то в общем случае производительность зависит от теста, на котором ее измеряют.
Для предиктора важна производительность на той программе, характеристики которой пользователь хочет предсказать. Поэтому наиболее точным является измерение производительности на исходной программе пользователя. Для этого надо выполнить эту программу на двух машинах (целевой и инструментальной), чтобы определить отношение производительностей. Однако это бывает затруднительно или накладно по времени и ресурсам.
Можно использовать более быстрый и удобный путь определения производительности, основанный на использовании единого теста. Информация о производительности процессоров известных ЭВМ на этом тесте может помещаться в папку DVM системы. Это позволяет избежать запуска теста на целевой системе.
Тест на производительность называется power.cdv находится в папке demo. Он состоит из нескольких интервалов. На каждом интервале замеряется некоторый объем вычислений. Для того чтобы получить производительность процессоров на каждом интервале, пользователь должен запустить программу (командой dvm run [<processor>] <имя_DVM-программы>). В результате получится столбец времен работы процессора при вычислениях в интервале. Такие столбцы строятся (либо пользователем, либо заранее системой) для каждой ЭВМ (всех целевых и инструментальной).
Пользователь должен понять, какой из интервалов теста наиболее близко отражает сложность его задачи. Для этого он прикидывает, какие циклы в его программе выполняются дольше других и какова их сложность (сколько арифметических операций выполняются на каждом витке цикла). Таким образом, сложность задачи пользователя измеряется в количестве арифметических операциях на один виток.
По этим данным о сложности задачи пользователь находит интервал теста и время его выполнения на каждой из машин (целевая и инструментальная). Пользователю надо получить отношение этих времен и задать его предиктору (в файле predictor.par, параметр - относительная производительность процессора).
Приложение 2. Связь имен полей в выходном HTML-файле и имен полей в структуре _IntervalResult
|
Имя поля |
|
|
Якорь |
Переменная inter |
|
|
|
|
|
|
|
Efficiency |
|
|
effic |
Efficiency |
|
Execution time |
|
|
exec |
Execution_time |
|
Total time |
|
|
total |
Total_time |
|
Productive time |
|
|
ptime |
Productive_time |
|
|
CPU |
|
ptimec |
Productive_CPU_time |
|
|
SYS |
|
ptimes |
Productive_SYS_time |
|
|
I/O |
|
ptimei |
IO_time |
|
Lost time |
|
|
lost |
Lost_time |
|
|
Insufficient parallelism |
|
insuf |
Insuff_parallelism |
|
|
|
USR |
iuser |
Insuff_parallelism_sys |
|
|
|
SYS |
isyst |
Insuff_parallelism_usr |
|
|
Communications |
|
comm |
Communication |
|
|
|
SYN |
csyn |
Communication_SYNCH |
|
|
Idle time |
|
idle |
Idle |
|
Load imbalance |
|
|
imbal |
Load_imbalance |
|
Synchronization |
|
|
synch |
Synchronization |
|
Time variation |
|
|
vary |
Time_variation |
|
Overlap |
|
|
over |
Overlap |
|
|
|
|
|
|
|
IO |
# op |
|
nopi |
num_op_io |
|
|
Communications |
|
comi |
IO_comm |
|
|
Real synch |
|
synchi |
IO_synch |
|
|
Overlap |
|
overi |
IO_overlap |
|
Reduction |
# op |
|
nopr |
num_op_reduct |
|
|
Communications |
|
comr |
Wait_reduction |
|
|
Real synch |
|
synchr |
Reduction_synch |
|
|
Overlap |
|
overr |
Reduction_overlap |
|
Shadow |
# op |
|
nops |
num_op_shadow |
|
|
Communications |
|
coms |
Wait_shadow |
|
|
Real synch |
|
synchs |
Shadow_synch |
|
|
Overlap |
|
overs |
Shadow_overlap |
|
Remote access |
# op |
|
nopa |
num_op_remote |
|
|
Communications |
|
coma |
Remote_access |
|
|
Real synch |
|
syncha |
Remote_synch |
|
|
Overlap |
|
overa |
Remote_overlap |
|
Redistribution |
# op |
|
nopd |
num_op_redist |
|
|
Communications |
|
comd |
Redistribution |
|
|
Real synch |
|
synchd |
Redistribution_synch |
|
|
Overlap |
|
overd |
Redistribution_overlap |
Приложение 3. Описание вспомогательных функций и классов
Ниже приводится описание функций и классов, используемых при реализации алгоритмов описанных в предыдущей главе.
Базовый класс для большинства классов.
class Space {
protected:
vector<long> SizeArray; // Размер каждого измерения
vector<long> MultArray; // Множитель для каждого измерения
public:
Space();
Space(long ARank,vector<long> ASizeArray,vector<long> MultArray);
Space(long ARank, long *ASizeArray);
Space(const Space &);
~Space();
Space & operator= (const Space &x);
long GetRank();
long GetSize(long AAxis);
long GetMult(long AAxis);
void GetSI(long LI, vector<long> & SI);
long GetLI(const vector<long> & SI);
long GetCenterLI();
long GetSpecLI(long LI, long dim, int shift);
long GetLSize();
long GetNumInDim(long LI, long dimNum);
long GetDistance(long LI1, long LI2);
};
|
GetRank |
– |
возвращает размерность пространства. |
|
GetSize |
– |
возвращает размер измерения с номером AAxis. |
|
GetMult |
– |
возвращает множитель для измерения с номером AAxis. |
|
GetSI |
– |
вычисляет координаты SI в данном пространстве по линейному индексу LI. |
|
GetLI |
– |
вычисляет линейный индекс по координатам в данном пространстве. |
|
GetCenterLI |
– |
возвращает линейный индекс элемента, являющегося геометрическим центром пространства. |
|
GetSpecLI |
– |
функция возвращает линейный индекс элемента, который смещён на shift по измерению dim от элемента заданного линейным индексом LI. |
|
GetLSize |
– |
возвращает линейный размер (число элементов) пространства. |
|
GetNumInDim |
– |
возвращает координату элемента, заданного линейным индексом LI, в данном измерении dimNum. |
|
GetDistance |
– |
расстояние между двумя элементами пространства заданными линейными индексами LI1 и LI2. |
Класс “Виртуальная машина” (“Процессорная система”).
class
VM : public Space {
const
VM* parent; // ссылка
на родительский VM
double
ProcPower;
// относительная мощность процессоров из VM
int
ProcCount;
// количество процессоров в VM
int
MType;
// Тип распределенной
системы процессоров
//
0 – сеть с шинной организацией,
1 – транспьютерная система, 2 —
myrinet
double
TStart;
// Время старта операции обмена
double
TByte;
// Время пересылки одного байта
std::vector<int>
mapping;
// отображение на абсолютные номера
процессоров
std::vector<double>
weight;
// вектор
весов PS
std::vector<double>
vProcPower;
// относительные производительности процессоров
std::vector<double>
vWeights;
// веса элементов
измерений установленной
процессорной
//
системы
public:
//
конструктор
VM(vector<long>&
ASizeArray, int AMType, double ATStart, double ATByte,
double
AprocPower);
~VM();
double
getTByte();
double
getTStart();
int
getMType();
void
SetvWeights(std::vector<double> &
varray);
double
getProcPower(int k);
int
getProcCount();
double
getProcPower();
int
getNumChanels();
double
getScale();
const
std::vector<long>& getSizeArray();
int
map(int i);
void
setWeight(const std::vector<double>& Aweight);
};
Класс “Представление абстрактной машины”.
class
WeightClass{
public:
long
ID;
// PS
, при отображении в которую
будут использоваться веса
std::vector<double>
body;
// заданные
веса
WeightClass();
WeightClass(long
AID,std::vector<double>&
init_weights);
void
GetWeights(std::vector<double> &
Aaweights);
void
SetWeights(long AID,std::vector<double>&
init_weights);
~WeightClass();
long
GetSize();
};
class AMView : public Space {
public:
VM
*VM_Dis;
// Система процессоров, на которую отображен шаблон
list<DArray
*> AlignArrays;
// Список выравненных на данный шаблон массивов
vector<DistAxis>
DistRule;
//Правило отображения шаблона в систему процессоров
vector<long>
FillArr;
// Массив с информацией о заполнении процессорной
//системы
элементами шаблона
int
Repl;
// признак полностью размноженного по AM_Dis массива
WeightClass
weightEl;
// веса для отображения шаблона
AMView(long
ARank, long *AsizeArray);
AMView(const AMView &);
~AMView();
long
GetMapDim(long arrDim, int & dir);
void DelDA(DArray
*RAln_da);
void AddDA(DArray *Aln_da);
void DisAM(VM
*AVM_Dis, long AParamCount, long
*AaxisArray,
long
*AdistrParamArray);
double
RDisAM(long AParamCount, long *AAxisArray, long
*AdistrParamArray,
long AnewSign);
bool IsDistribute();
};
|
DelDA |
- |
удаляет распределенный массив DArray из списка выравненных массивов. |
|
AddDA |
- |
добавляет распределенный массив DArray в список выравненных массивов. |
|
DisAM |
- |
функция отображения шаблона в систему процессоров. Производится инициализация указателя на систему процессоров, правила отображения и массив с информацией о заполнении процессорной системы элементами шаблона в соответствии с параметрами функции. |
|
RdisAM |
- |
функция определения времени затрачиваемого на обмены при изменении отображения шаблона в систему процессоров (перераспределение шаблона). Алгоритм, реализуемый ею, описан в п.4.2. |
|
IsDistribute |
- |
проверяет, распределен ли уже шаблон на систему процессоров. |
Класс “ распределенный массив”.
class
DArray
:
public
Space
{
private:
void
PrepareAlign(long& TempRank, long *AAxisArray, long
*AcoeffArray,
long
*AConstArray, vector<AlignAxis>&
IniRule);
long
CheckIndex(long *InitIndexArray, long *LastIndexArray, long
*StepArray);
public:
std::vector<long>
LowShdWidthArray;
std::vector<long>
HiShdWidthArray;
long
TypeSize;
// Размер
в байтах
одного
элемента
массива
AMView
*AM_Dis;
// Шаблон по которому выравнен данный массив
vector<AlignAxis>
AlignRule
// Правило выравнивания массива на шаблон
int
Repl;
// признак полностью размноженного по шаблону массива
Darray();
DArray(const
std::vector<long>& ASizeArray, const
std::vector<long>&ALowShdWidthArray,
const
std::vector<long>& AHiShdWidthArray, int ATypeSize);
DArray(const
DArray &);
~Darray();
DArray &
operator= (DArray &x);
void
AlnDA(AMView *APattern, long *AAxisArray, long
*AcoeffArray,
long
*AconstArray);
void
AlnDA(DArray *APattern, long *AAxisArray, long
*AcoeffArray,
long
*AconstArray);
double
RAlnDA(AMView *APattern, long *AAxisArray,
long *AcoeffArray,
long *AConstArray,
long AnewSign);
double
RAlnDA(DArray *APattern, long *AAxisArray, long
*AcoeffArray,
long
*AConstArray, long AnewSign);
friend
double ArrayCopy( DArray* AFromArray,
const
std::vector<long>& AFromInitIndexArray,
const
std::vector<long>& AFromLastIndexArray,
const
std::vector<long>& AFromStepArray,
DArray*
AToArray,
const
std::vector<long>& AToInitIndexArray,
const
std::vector<long>& AToLastIndexArray,
const
std::vector<long>& AToStepArray);
friend
double ArrayCopy(DArray* AFromArray,
const
std::vector<long>& AFromInitIndexArray,
const
std::vector<long>& AFromLastIndexArray,
const
std::vector<long>& AFromStepArray,
long
AcopyRegim);
long
GetMapDim(long arrDim, int &dir);
bool
IsAlign();
double
RDisDA(const std::vector<long>& AAxisArray,
const
std::vector<long>& ADistrParamArray, long
AnewSign);
};
|
PrepareAlign |
– |
инициализирует правило выравнивания массива на образец выравнивания. |
|
CheckIndex |
– |
возвращает число элементов в секции данного массива, заданной параметрами функции ( 0 – если она пуста или индексы вышли за пределы массива). |
|
AlnDA |
– |
функции задания расположения (выравнивания) распределенного массива. Во второй функции производится косвенное задание шаблона через распределенный массив. Производится инициализация указателя на шаблон. В первой функции производится определение признака полностью размноженного по шаблону массива, во второй же он наследуется у массива, выступающего в качестве образца отображения. Также в первой функции производится инициализация правила выравнивания массива на шаблон при помощи функции PrepareAlign, а во второй, кроме этого, производится изменение полученного правила с учетом того, как выравнен образец, по которому выравнивается данный массив (т.е. осуществляется суперпозиция выравниваний, для получения результирующего выравнивания массива на шаблон). |
|
RAlnDA |
– |
функция определения времени, затрачиваемого на обмены при повторном выравнивании массива на шаблон. Алгоритм, реализуемый ею, описан в п.4.2. |
|
ArrayCopy |
– |
функция определения времени затрачиваемого на обмены при загрузке буферов удаленными элементами массива. (Алгоритм описан в п.4.5.) |
|
GetMapDim |
– |
функция возвращает номер измерения системы процессоров, на которое в итоге отображено указанное измерение массива arrDim. Если измерение массива размножено по всем направлениям матрицы процессоров, то возвращается 0. В dir заносится 1 или -1 в зависимости от направления разбиения измерения массива. |
|
IsAlign |
– |
проверяет, выравнен ли уже массив на шаблон. |
|
RDisDA |
– |
функция определения времени затрачиваемого на обмены при перераспределении массива. |
Класс ”Группа границ”.
class
BoundGroup {
CommCost boundCost;
// Информация об обменах между
процессорами
public:
std::vector<DimBound>
dimInfo;
// Информация о границах по размерностям
AMView *amPtr;
// Шаблон, по которому выравнены массивы, чьи границы
// добавлены в данную
группу
BoundGroup();
virtual
~BoundGroup();
void AddBound(DArray *ADArray, long
*ALeftBSizeArray,
long
*ARightBSizeArray, long AcornerSign);
CommCost*
GetBoundCost();
double StartB();
};
|
AddBound |
– |
включение границы распределенного массива в группу границ. (Алгоритм описан в п.4.3.) |
|
StartB |
– |
функция определения времени затрачиваемого на обмены границами распределенных массивов, включенными в данную группу. (Алгоритм описан в п.4.3.) |
Класс “Редукционная переменная”.
class RedVar {
public:
long RedElmSize; //Размер элемента редукционной переменной - массива в
//байтах
long RedArrLength; //Число элементов в редукционной переменной-массиве
long LocElmSize; //Размер в байтах одного элемента массива с дополнительной
//информацией
RedVar(long ARedElmSize, long ARedArrLength, long ALocElmSize);
RedVar();
virtual ~RedVar();
long GetSize();
};
|
GetSize |
– |
возвращает размер в байтах редукционной переменной-массива вместе с массивом дополнительной информации. |
Класс “Редукционная группа”.
class RedGroup {
public:
VM *vmPtr; // Указатель на систему процессоров
vector<RedVar *> redVars; // Массив редукционных переменных
long TotalSize; // Общий размер в байтах редукционных переменных
// включенных в группу с их дополнительной информации
long CentralProc; // Линейный индекс геометрического центра системы
// процессоров
RedGroup(VM *AvmPtr);
virtual ~RedGroup();
void AddRV(RedVar *ARedVar);
double StartR(DArray *APattern, long ALoopRank, long *AAxisArray);
double StartR(AMView *APattern, long ALoopRank, long *AAxisArray);
};
|
void AddRV |
– |
функция включения редукционной переменной в редукционную группу.( Алгоритм описан в п.4.4). |
|
StartR |
– |
функция возвращающая время затрачиваемое на обмены при выполнении операций редукции. (Алгоритм описан в п.4.4). |
Класс “Распределение измерения массива”.
class DistAxis {
public:
long Attr; // Тип распределения
long Axis; // Номер измерения шаблона
long PAxis; // Номер измерения системы процессоров
DistAxis(long AAttr, long AAxis, long APAxis);
DistAxis();
virtual ~DistAxis();
DistAxis& operator= (const DistAxis&);
friend bool operator == (const DistAxis& x, const DistAxis& y);
friend bool operator < (const DistAxis& x, const DistAxis& y);
};Класс “Выравнивание измерения распределенного массива на шаблон”.
class AlignAxis {
public:
long Attr; // Тип выравнивания
long Axis; // Номер измерение массива
long TAxis; // Номер измерения шаблона
long A; // Коэффициент для индексной переменной распределенного
// массива в линейном правиле выравнивания TAxis-го *
// измерения шаблона
long B; // Константа линейного правила выравнивания для TAxis-го
// измерения шаблона
long Bound; // Размер измерения массива выступающего в качестве образца
// выравнивания при частично размножении выравниваемого
// массива
AlignAxis(long AAttr, long AAxis, long ATAxis, long AA = 0, long AB = 0, long ABound = 0);
AlignAxis();
virtual ~AlignAxis();
AlignAxis& operator= (const AlignAxis&);
friend bool operator==(const AlignAxis& x, const AlignAxis& y);
friend bool operator<(const AlignAxis& x, const AlignAxis& y);
};Класс “Теневая грань по одному измерению распределенного массива”.
class DimBound {
public:
long arrDim; // Номер измерения массива
long vmDim; // Номер измерения системы процессоров
int dir; // Равно 1 или -1 в зависимости от направления разбиения
// измерения массива
long LeftBSize; // Ширина левой границы для arrDim-го измерения массива
long RightBSize; // Ширина правой границы для arrDim-го измерения массива
DimBound(long AarrDim, long AvmDim, int Adir, long ALeftBSize, long ARightBSize);
DimBound();
virtual ~DimBound();
};Класс “Секция массива”.
class Block {
vector<LS> LSDim; // Вектор, содержащий соответствующие линейные сегменты,
// для каждого измерения массива, описывающие данную секцию
public:
Block(vector<LS> &v);
Block(DArray *da, long ProcLI);
Block(DArray *da, long ProcLI,int a); // a – не значащий параметр
Block();
virtual ~Block();
Block & operator =(const Block & x);
long GetRank();
long GetBlockSize();
long GetBlockSizeMult(long dim);
long GetBlockSizeMult2(long dim1, long dim2);
bool IsLeft(long arrDim, long elem);
bool IsRight(long arrDim, long elem);
bool IsBoundIn(long *ALeftBSizeArray,long *ARightBSizeArray);
bool empty();
friend Block operator^ (Block &x, Block &y);
long GetUpper(long i);
long GetLower(long i);
};
|
Block |
– |
создает секцию массива da, лежащую на процессоре с линейным индексом ProcLI. |
|
GetRank |
– |
возвращает размерность секции. |
|
GetBlockSize |
– |
число элементов в секции. |
|
GetBlockSizeMult, |
– |
данные функции возвращают произведение размеров секции по каждому измерению кроме указанных при обращении к ним. |
|
IsLeft, IsRight |
– |
проверка того, что по данному измерению arrDim элемент elem находится левее (правее) данной секции |
|
IsBoundIn |
– |
проверка на не выход границы распределенного массива за пределы данной секции. |
|
Empty |
– |
проверка секции на отсутствие элементов. |
|
Block operator^ |
– |
возвращает секцию, являющуюся пересечением секций заданных при обращении к функции. |
|
GetUpper |
– |
возвращает верхнюю границу блока по i-тому измерению |
|
GetLower |
– |
возвращает нижнюю границу блока по i-тому измерению |
Класс “Линейный сегмент”.
class
LS
{
long
Lower;
// Нижнее значение индекса
long
Upper;
// Верхнее значение индекса
long
Stride;
// Шаг
индексов
public:
LS(long
ALower, long Aupper);
LS();
virtual
~LS();
long
GetLSSize();
void
transform(long A, long B, long daDimSize);
bool
IsLeft(long elem);
bool
IsRight(long elem);
bool
IsBoundIn(long ALeftBSize, long ARightBSize);
bool
IsEmpty();
LS
operator^ (LS &x);
friend
bool operator==(const LS& x, const LS&
y);
friend
bool operator<(const LS& x, const LS&
y);
long
GetLower();
long
GetUpper();
};
|
GetLSSize |
– |
возвращает размер линейного сегмента. |
|
Transform |
– |
преобразует линейный сегмент шаблона в линейный сегмент распределенного массива выравненного по данному шаблону. |
|
IsLeft, IsRight |
– |
проверка того, что элемент elem находится левее (правее) данного сегмента. |
|
IsBoundIn |
– |
проверка на не выход заданной границы за пределы сегмента. |
|
IsEmpty |
– |
проверка сегмента на отсутствие элементов. |
|
LS operator^ |
– |
оператор пересечения сегментов. |
|
GetUpper |
– |
возвращает верхнюю границу сегмента |
|
GetLower |
– |
возвращает нижнюю границу сегмента |
Класс “Оценка обменов между процессорами”.
class CommCost {
public:
Dim2Array transfer; // Массив содержащий информацию о количестве байтов
// пересылаемых между парой процессоров
VM *vm; // Указатель на систему процессоров
CommCost(VM *Avm);
CommCost();
virtual ~CommCost();
CommCost & operator =(const CommCost &);
double GetCost();
void Update(DArray *oldDA, DArray *newDA);
void BoundUpdate(DArray *daPtr, vector<DimBound> & dimInfo, bool IsConer);
void CopyUpdate(DArray *FromArray, Block & readBlock);
void CopyUpdateDistr(DArray * FromArray, Block &readBlock, long p1);
long GetLSize();
void Across(double call_time, long LoopSZ, LoopBlock** ProcBlock,int type_size);
};
|
GetCost |
– |
функция возвращает время, затрачиваемое на обмены между процессорами системы. (Алгоритм описан в п.4.2). |
|
Update |
– |
функция для изменения массива transfer в соответствии с обменами, возникающими между процессорами при переходе от одного распределения массива к другому. Алгоритм, реализуемый ею, описан в п.4.2. |
|
BoundUpdate |
– |
функция для изменения массива transfer в соответствии с пересылками, возникающими при обмене границей заданного распределенного массива. (Алгоритм описан в п.4.3). |
|
CopyUpdate |
– |
функция изменения массива transfer в соответствии с обменами, возникающими при размножении секции readBlock массива FromArray по всем процессорам. (Алгоритм описан в п.4.3). |
|
CopyUpdateDistr |
– |
функция изменения массива transfer в соответствии с обменами, возникающими при копировании секции readBlock массива FromArray от всех процессоров к процессору p1. (Алгоритм описан в п.4.3). |
|
GetLSize |
– |
функция возвращает размер вектора vm. |
|
Across |
– |
функция расчета оптимального количества квантов конвейерной обработки цикла размера LoopSZArg, выполненного на 1 процессоре за call_timeArg. При этом передается разбиение витков цикла по процессорам через параметр ProcBlockArg и тип type_size передаваемого в конвейере элемента массива. (Алгоритм описан в п.4.6). |
Приложение 4. Основные функции экстраполятора времени
Конструктор объекта “Виртуальная машина”
VM::VM( vector<long>
ASizeArray, int AMType, double ATStart, double
ATByte,
double
AProcPower );
|
ASizeArray |
– |
вектор, i-й элемент которого содержит размер данной системы процессоров по измерению i + 1 (0 <= i <= ARank – 1); |
|
AMType |
– |
тип распределенной системы процессоров (0 – сеть с шинной организацией, 1 – транспьютерная система); |
|
ATStart |
– |
время старта операции обмена; |
|
ATByte |
– |
время пересылки одного байта; |
|
AProcPower |
– |
относительная производительность процессора. |
Конструктор объекта “Представление абстрактной машины”
AMView::AMView( vector< long> ASizeArray );
|
ASizeArray |
– |
вектор, i-й элемент которого содержит размер данного шаблона по измерению i + 1 (0 <= i <= ARank – 1); |
Отображение шаблона
void
AMView::DisAM (ImLastVM *AVM_Dis, vector<long>
AAxisArray,
vector<long>
*ADistrParamArray );
|
AVM_Dis |
– |
ссылка на систему процессоров, на которую отображается шаблон. |
|
AAxisArray |
– |
вектор, j-й элемент которого содержит номер измерения шаблона, используемый в правиле отображения для (j+1)-го измерения системы процессоров. |
|
ADistrParamArray |
– |
игнорируется (т.е. обеспечиваются только два правила отображения: 1 и 2 (см. описание Lib-DVM). Причем в 1-ом правиле размер блока вычисляется, а не берется из ADistrParamArray). |
Задание перераспределения шаблона на систему процессоров и определение времени такого перераспределения.
double
AMView::RdisAM( vector<long> AAxisArray,
vector<long>
ADistrParamArray, long ANewSign );
|
AAxisArray |
– |
массив, j-й элемент которого содержит номер измерения шаблона, используемый в правиле отображения для (j+1)-го измерения системы процессоров. |
|
ADistrParamArray |
– |
игнорируется (т.е. обеспечиваются только два правила отображения: 1 и 2 (см. описание Lib-DVM). Причем в 1-ом правиле размер блока вычисляется, а не берется из ADistrParamArray). |
|
ANewSign |
– |
задаваемый единицей признак обновления содержимого всех перераспределяемых массивов. |
Конструктор объекта “ Распределенный массив”
DArray::DArray(
vector<long> ASizeArray, vector<long>
AlowShdWidthArray,
vector<long>
AhiShdWidthArray, long ATypeSize );
|
ASizeArray |
– |
вектор, i-й элемент которого содержит размер создаваемого массива по измерению i+1 (0 <= i <= ARank–1). |
|
AlowShdWidthArray |
– |
вектор, i-ый элемент которого содержит ширину левой границы по измерению i+1. |
|
AHiShdWidthArray |
– |
вектор, i-ый элемент которого содержит ширину правой границы по измерению i+1. |
|
ATypeSize |
– |
размер в байтах одного элемента массива. |
Выравнивание распределенного массива
void
DArray::AlnDA( AMView *APattern, vector<long>
AAxisArray,
vector<long>
ACoeffArray, vector<long> AConstArray );
void
DArray::AlnDA( DArray *APattern, vector<long>
AAxisArray,
vector<long>
ACoeffArray, vector<long> AConstArray );
|
APattern |
– |
ссылка на образец выравнивания. |
|
AAxisArray |
– |
вектор, j-й элемент которого содержит номер индексной переменной (номер измерения) распределенного массива для линейного правила выравнивания (j+1)-го измерения образца. |
|
ACoeffArray |
– |
вектор, j-й элемент которого содержит коэффициент для индексной переменной распределенного массива в линейном правиле выравнивания (j+1)-го измерения образца. |
|
AConstArray |
– |
вектор, j-й элемент которого содержит константу линейного правила выравнивания для (j+1)-го измерения образца. |
Повторное выравнивание распределенного массива и определение времени выполнения этой операции.
double
DArray::RAlnDA( AMView *APattern, vector<long>
AAxisArray,
vector<long>
ACoeffArray, vector<long>
AConstArray,
long
ANewSign );
double
DArray::RAlnDA( DArray *APattern, vector<long> AAxisArray,
vector<long>
ACoeffArray, vector<long>
AConstArray,
long ANewSign );
|
APattern |
– |
ссылка на образец выравнивания (массив или шаблон). |
|
AAxisArray |
– |
вектор, j-й элемент которого содержит номер индексной переменной (номер измерения) распределенного массива для линейного правила выравнивания (j+1)-го измерения образца. |
|
ACoeffArray |
– |
вектор, j-й элемент которого содержит коэффициент для индексной переменной распределенного массива в линейном правиле выравнивания (j+1)-го измерения образца. |
|
AconstArray |
– |
вектор, j-й элемент которого содержит константу линейного правила выравнивания для (j+1)-го измерения образца. |
|
ANewSign |
– |
задаваемый единицей признак обновления содержимого распределенного массива. |
Функция возвращает время повторного выравнивания массива.
Конструктор объекта “ параллельный цикл”
ParLoop::ParLoop( long ARank );
|
ARank |
– |
размерность параллельного цикла. |
Создание параллельного цикла.
void
ParLoop::MapPL( AMView *APattern, vector<long>
AAxisArray,
vector<long>
ACoeffArray, vector<long>
AConstArray,
vector<long>
AInitIndexArray,
vector<long>
ALastIndexArray, vector<long> AStepArray );
void
ParLoop::MapPL( DArray *APattern, vector<long>
AAxisArray,
vector<long>
ACoeffArray,
vector<long>AConstArray,
vector<long>AInitIndexArray,
vector<long>
ALastIndexArray, vector<long>AStepArray );
|
APattern |
– |
ссылка на образец отображения параллельного цикла. |
|
AAxisArray |
– |
вектор, j-й элемент которого содержит номер индексной переменной (номер измерения) параллельного цикла для линейного правила выравнивания (j+1)-го измерения образца. |
|
ACoeffArray |
– |
вектор, j-й элемент которого содержит коэффициент для индексной переменной параллельного цикла в линейном правиле выравнивания (j+1)-го измерения образца. |
|
AConstArray |
– |
вектор, j-й элемент которого содержит константу линейного правила выравнивания для (j+1)-го измерения образца. |
|
AInitIndexArray |
– |
вектор, i-ый элемент которого содержит начальное значение индексной переменной (i+1)-го измерения параллельного цикла. |
|
ALastIndexArray |
– |
вектор, i-ый элемент которого содержит конечное значение индексной переменной (i+1)-го измерения параллельного цикла. |
|
AStepArray |
– |
вектор, i-ый элемент которого содержит значение шага для индексной переменной (i+1)-го измерения параллельного цикла. |
Отображение параллельного цикла.
void ParLoop::ExFirst( ParLoop *AParLoop, BoundGroup *ABoundGroup)ImLast;
|
AParLoop |
– |
ссылка на параллельный цикл. |
|
ABoundGroup |
– |
ссылка на группу границ, обмен которыми должен быть запущен после вычисления экспортируемых элементов локальных частей распределенных массивов. |
Выставить флаг изменения порядка выполнения витков циклов.
void ParLoop::ImLast( ParLoop *AParLoop, BoundGroup *ABoundGroup)ImLast;
|
AParLoop |
– |
ссылка на параллельный цикл. |
|
ABoundGroup |
– |
ссылка на группу границ, обмен которыми должен быть запущен после вычисления экспортируемых элементов локальных частей распределенных массивов. |
Функция выставляет флаг изменения порядка выполнения витков циклов.
Определение времени затрачиваемого на обмены при загрузке буферов удаленными элементами массива
double
ArrayCopy( DArray *AFromArray, vector<long>
AFromInitIndexArray,
vector<long>
AFromLastIndexArray,
vector<long>
AFromStepArray, DArray
*AToArray,
vector<long>
AToInitIndexArray,
vector<long>
AToLastIndexArray,
vector<long>
AToStepArray, long ACopyRegim );
|
AFromArray |
– |
ссылка на читаемый распределенный массив. |
|
AFromInitIndexArray |
– |
вектор, i-й элемент которого содержит начальное значение индекса для (i+1)-го измерения читаемого массива. |
|
AFromLastIndexArray |
– |
вектор, i-й элемент которого содержит конечное значение индекса для (i+1)-го измерения читаемого массива. |
|
AFromStepArray |
– |
вектор, i-й элемент которого содержит шаг изменения индекса для (i+1)-го измерения читаемого массива. |
|
AToArray |
– |
заголовок записываемого распределенного массива. |
|
AToInitIndexArray |
– |
вектор, j-й элемент которого содержит начальное значение индекса для (j+1)-го измерения записываемого массива. |
|
AToLastIndexArray |
– |
вектор, j-й элемент которого содержит конечное значение индекса для (j+1)-го измерения записываемого массива. |
|
AToStepArray |
– |
вектор, j-й элемент которого содержит шаг изменения индекса для (j+1)-го измерения записываемого массива. |
|
ACopyRegim |
– |
режим копирования. |
Функция возвращает искомое время.
Конструктор объекта “Группа границ”
BoundGroup::BoundGroup( );
Создание группы границ. Создается пустая группа границ (не содержащая ни одной границы).
Добавить границы массива в группу.
void
BoundGroup::AddBound( DArray *ADArray, vector<long>
ALeftBSizeArray,
vector<long>
ARightBSizeArray,
long
ACornerSign);
|
ADArray |
– |
ссылка на распределенный массив. |
|
ALeftBSizeArray |
– |
вектор, i-й элемент которого содержит ширину нижней границы для (i+1)-го измерения массива. |
|
ARightBSizeArray |
– |
вектор, i-й элемент которого содержит ширину верхней границы для (i+1)-го измерения массива. |
|
ACornerSign |
– |
признак включения в границу угловых элементов. |
Определение времени затрачиваемого на обмены границами распределенных массивов, включенных в данную группу.
double BoundGroup::StartB( );
Функция возвращает искомое время.
Конструктор объекта “Редукционная переменная”
RedVar::RedVar( long ARedElmSize, long ARedArrLength, long ALocElmSize);
|
AredElmSize |
– |
размер одного элемента редукционной переменной-массива в байтах. |
|
ARedArrLength |
– |
число элементов в редукционной переменной-массиве. |
|
ALocElmSize |
– |
размер в байтах одного элемента массива с дополнительной информацией. |
Конструктор объекта “Редукционная группа”
RedGroup::RedGroup( VM *AvmPtr );
|
AvmPtr |
– |
ссылка на систему процессоров. |
Создание редукционной группы. Создается пустая редукционная группа (не содержащая ни одной редукционной переменной).
Включение редукционной переменной в редукционную группу.
void RedGroup::AddRV( RedVar *AredVar );
|
ARedVar |
– |
ссылка на редукционную переменную. |
Определение времени затрачиваемого на обмены при выполнении операций редукции.
double RedGroup::StartR( ParLoop *AParLoop );
|
AParLoop |
– |
ссылка на параллельный цикл, в котором вычисляются значения редукционных переменных из данной группы. |
Приложение 5. Фрагменты трассы и параметры моделируемых Предиктором функций Lib-DVM
ПОСТРОЕНИЕ ПРЕДСТАВЛЕНИЙ АБСТРАКТНОЙ МАШИНЫ
getamr_ 3.3 Опрос ссылки на элемент представления абстрактной машины
AMRef getamr_ (AMViewRef *AMViewRefPtr, long IndexArray[]);
|
*AMViewRefPtr |
– |
ссылка на представление абстрактной машины. |
|
IndexArray |
– |
массив, i-й элемент которого содержит значение индекса опрашиваемого элемента (т.е. абстрактной машины) по измерению i+1. |
call_getamr_ TIME=0.000000 LINE=6 FILE=tasks.fdv AMViewRefPtr=4dff90; AMViewRef=9024c0; IndexArray[0]=0; ret_getamr_ TIME=0.000000 LINE=6 FILE=tasks.fdv AMRef=903350;
МНОГОПРОЦЕССОРНЫЕ СИСТЕМЫ
genblk_ Веса элементов многопроцессорной системы
long
genblk_(PSRef *PSRefPtr, AMViewRef
*AMViewRefPtr,
AddrType
AxisWeightAddr[], long *AxisCountPtr,
long
*DoubleSignPtr );
|
*PSRefPtr |
– |
ссылка на многопроцессорную систему, для элементов которой устанавливаются веса. |
|
*AMViewRefPtr |
– |
ссылка на представление абстрактной машины, при oтображении которой в заданную процессорную систему будут использованы устанавливаемые веса координат. |
|
AxisWeightAddr[] |
– |
веса координат процессоров задаются в отдельном для каждого измерения процессорной системы. |
|
*AxisCountPtr |
– |
(неотрицательное целое число) задаёт количество элементов в массиве AxisWeightAddr. |
|
*DoubleSignPtr |
– |
ненулевой признак представления весов координат процессоров в виде вещественных положительных чисел (double). |
call_genblk_ TIME=0.000000 LINE=7 FILE=gausgb.fdv PSRefPtr=4d4c48; PSRef=8417d0; AMViewRefPtr=4d4c60; AMViewRef=842860; AxisCount=1; DoubleSign=0 AxisWeightAddr[0][0] = 3 ret_genblk_ TIME=0.000000 LINE=7 FILE=gausgb.fdv
crtps_ 4.2 Создание подсистемы заданной многопроцессорной системы
PSRef crtps_
(PSRef *PSRefPtr, long InitIndexArray[], long
LastIndexArray[],
long
*StaticSignPtr);
|
*PSRefPtr |
– |
ссылка на процессорную систему (исходную), подсистему которой требуется создать. |
|
InitIndexArray |
– |
массив, i-й элемент которого содержит начальное значение индекса исходной процессорной системы по измерению i+1. |
|
LastIndexArray |
– |
массив, i-й элемент которого содержит конечное значение ндекса исходной процессорной системы по измерению i+1. |
|
*StaticSignPtr |
– |
признак создания статической подсистемы. |
call_crtps_ TIME=0.000000 LINE=15 FILE=tasks.fdv
PSRefPtr=4ded68; PSRef=902450; StaticSign=0;
InitIndexArray[0]=0;
LastIndexArray[0]=0;
SizeArray[0]=1;
CoordWeight[0]= 1.00(1.00)
ret_crtps_ TIME=0.000000 LINE=15 FILE=tasks.fdv
PSRef=903950;psview_ 4.3 Реконфигурация (изменение формы) многопроцессорной системы
PSRef psview_
(PSRef *PSRefPtr, long *RankPtr, long
SizeArray[],
long
*StaticSignPtr);
|
*PSRefPtr |
– |
ссылка на исходную (реконфигурируемую) процессорную систему. |
|
*RankPtr |
– |
размерность результирующей (реконфигурированной) процессорной системы. |
|
SizeArray |
– |
массив, i-й элемент которого содержит размер результирующей процессорной системы по измерению i+1. |
|
*StaticSignPtr |
– |
признак статической результирующей процессорной системы. |
call_psview_ TIME=0.000000 LINE=6 FILE=tasks.fdv
PSRefPtr=4dff84; PSRef=901330; Rank=1; StaticSign=0;
SizeArray[0]=1;
SizeArray[0]=1;
CoordWeight[0]= 1.00(1.00)
ret_psview_ TIME=0.000000 LINE=6 FILE=tasks.fdv
PSRef=902450;ОТОБРАЖЕНИЕ РАСПРЕДЕЛЕННОГО МАССИВА
getamv_ 7.8 Опрос ссылки на представление абстрактной машины, в которое отображён заданный распределённый массив
AMViewRef getamv_ (long * ArrayHeader);
|
ArrayHeader |
– |
заголовок распределённого массива. |
call_getamv_ TIME=0.000000 LINE=16 FILE=tasks.fdv ArrayHeader=4dfee8; ArrayHandlePtr=903530; ret_getamv_ TIME=0.000000 LINE=16 FILE=tasks.fdv AMViewRef=0;
ПРЕДСТАВЛЕНИЕ ПРОГРАММЫ В ВИДЕ
СОВОКУПНОСТИ
ПАРАЛЛЕЛЬНО ВЫПОЛНЯЮЩИХСЯ ПОДЗАДАЧ
mapam_ 10.1 Отображение абстрактной машины (создание подзадачи)
long mapam_ (AMRef *AMRefPtr, PSRef *PSRefPtr );
|
*AMRefPtr |
– |
ссылка на отображаемую абстрактную машину. |
|
*PSRefPtr |
– |
ссылка на процессорную подсистему, определяющую состав выделяемых абстрактной машине процессоров (область выполнения создаваемой подзадачи). |
call_mapam_ TIME=0.000000 LINE=51 FILE=tsk_ra.cdv AMRefPtr=4b3cc0; AMRef=823210; PSRefPtr=4b3ec4; PSRef=8231a0; ret_mapam_ TIME=0.000000 LINE=51 FILE=tsk_ra.cdv
runam_ 10.2 Начало выполнения (активизация, пуск) подзадачи
long runam_ (AMRef *AMRefPtr);
|
*AMRefPtr |
– |
ссылка на абстрактную машину запускаемой подзадачи. |
call_runam_ TIME=0.000000 LINE=102 FILE=tsk_ra.cdv AMRefPtr=4b3cc0; AMRef=823210; ret_runam_ TIME=0.000000 LINE=102 FILE=tsk_ra.cdv
stopam_ 10.3 Завершение выполнения (останов) текущей подзадачи
long stopam_ (void);
call_stopam_ TIME=0.000000 LINE=104 FILE=tsk_ra.cdv ret_stopam_ TIME=0.000000 LINE=104 FILE=tsk_ra.cdv
РЕДУКЦИЯ
strtrd_ 11.5 Запуск редукционной группы
long strtrd_ (RedGroupRef *RedGroupRefPtr);
|
*RedGroupRefPtr |
– |
ссылка на редукционную группу. |
call_strtrd_ TIME=0.000000 LINE=129 FILE=tsk_ra.cdv RedGroupRefPtr=6ffcdc; RedGroupRef=8291f0; rf_MAX; rt_DOUBLE; RVAddr = 6ffd24; RVVal = 7.000000 ret_strtrd_ TIME=0.000000 LINE=129 FILE=tsk_ra.cdv
waitrd_ 11.6 Ожидание завершения редукции
long waitrd_ (RedGroupRef *RedGroupRefPtr);
|
*RedGroupRefPtr |
– |
ссылка на редукционную группу. |
call_waitrd_ TIME=0.000000 LINE=129 FILE=tsk_ra.cdv RedGroupRefPtr=6ffcdc; RedGroupRef=8291f0; rf_MAX; rt_DOUBLE; RVAddr = 6ffd24; RVVal = 7.000000 rf_MAX; rt_DOUBLE; RVAddr = 6ffd24; RVVal = 7.000000 ret_waitrd_ TIME=0.000000 LINE=129 FILE=tsk_ra.cdv
ОБМЕН ГРАНИЦАМИ РАСПРЕДЕЛЕННЫХ МАССИВОВ
recvsh_ 12.4 Инициализация приема импортируемых элементов заданной группы границ
long recvsh_(ShadowGroupRefPtr *ShadowGroupRefPtr);
|
*ShadowGroupRefPtr |
– |
ссылка на группу границ. |
call_recvsh_ TIME=0.000000 LINE=20 FILE=sor.fdv ShadowGroupRefPtr=4cf6b8; ShadowGroupRef=8433c0; ret_recvsh_ TIME=0.000000 LINE=20 FILE=sor.fdv
sendsh_ 12.5 Инициализация передачи экспортируемых элементов заданной группы границ
long sendsh_(ShadowGroupRefPtr *ShadowGroupRefPtr);
|
*ShadowGroupRefPtr |
– |
ссылка на группу границ. |
call_sendsh_ TIME=0.000000 LINE=29 FILE=sor.fdv ShadowGroupRefPtr=4cf6b8; ShadowGroupRef=8433c0; ret_sendsh_ TIME=0.000000 LINE=29 FILE=sor.fdv
РЕГУЛЯРНЫЙ ДОСТУП К УДАЛЕННЫМ ДАННЫМ
crtrbl_ 14.1 Создание буфера удалённых элементов распределённого массива
long
crtrbl_(long RemArrayHeader[], long BufferHeader[], void
*BasePtr,
long
*StaticSignPtr, LoopRef *LoopRefPtr, long
AxisArray[],
long
CoeffArray[], long ConstArray[]);
|
RemArrayHeader |
– |
заголовок удалённого распределённого массива. |
|
BufferHeader |
– |
заголовок создаваемого буфера удалённых элементов. |
|
BasePtr |
– |
базовый указатель для доступа к буферу удалённых элементов. |
|
*StaticSignPtr |
– |
признак создания статического буфера. |
|
*LoopRefPtr |
– |
ссылка на параллельный цикл, при выполнении которого необходимы размещённые в буфере элементы удалённого массива. |
|
AxisArray |
– |
массив i-й элемент которого содержит номер измерения параллельного цикла (k(i+1)), соответствующего (i+1)-му измерению удалённого массива. |
|
CoeffArray |
– |
массив, i-й элемент которого содержит коэффициент индексной переменной линейного правила выборки для (i+1)-го измерения удалённого массива A(i+1). |
|
ConstArray |
– |
массив, i-й элемент которого содержит константу линейного правила выборки для (i+1)-го измерения удалённого массива B(i+1). |
call_crtrbl_ TIME=0.000000 LINE=45 FILE=tasks.fdv
RemArrayHeader=4dfd2c; RemArrayHandlePtr=9057c0; BufferHeader=4dfd48;
BasePtr=4e1200; StaticSign=1; LoopRefPtr=4dffd0; LoopRef=906b70;
AxisArray[0]=1; AxisArray[1]=0;
CoeffArray[0]=1; CoeffArray[1]=0;
ConstArray[0]=-1; ConstArray[1]=1;
SizeArray[0]=8;
LowShdWidthArray[0]=0;
HiShdWidthArray[0]=0;
Local[0]: Lower=0 Upper=7 Size=8 Step=1
ret_crtrbl_ TIME=0.000000 LINE=45 FILE=tasks.fdv
BufferHandlePtr=906e70; IsLocal=1loadrb_ 14.2 Запуск загрузки буфера удаленных элементов распределенного массива
long loadrb_ (long BufferHeader[], long *RenewSignPtr);
|
BufferHeader |
– |
заголовок буфера удаленных элементов. |
|
*RenewSignPtr |
– |
признак повторной перезагрузки уже загруженного буфера. |
call_loadrb_ TIME=0.000000 LINE=45 FILE=tasks.fdv
BufferHeader=4dfd48; BufferHandlePtr=906e70; RenewSign=0;
FromInitIndexArray[0]=0; FromInitIndexArray[1]=1;
FromLastIndexArray[0]=7; FromLastIndexArray[1]=1;
FromStepArray[0]=1; FromStepArray[1]=1;
ToInitIndexArray[0]=0;
ToLastIndexArray[0]=7;
ToStepArray[0]=1;
ResInitIndexArray[0]=0; ResInitIndexArray[1]=1;
ResLastIndexArray[0]=7; ResLastIndexArray[1]=1;
ResStepArray[0]=1; ResStepArray[1]=1;
ResInitIndexArray[0]=0;
ResLastIndexArray[0]=7;
ResStepArray[0]=1;
ret_loadrb_ TIME=0.000000 LINE=45 FILE=tasks.fdvwaitrb_ 14.3 Ожидание завершения загрузки буфера удаленных элементов распределенного массива
long waitrb_ (long BufferHeader[]);
|
BufferHeader |
– |
заголовок буфера удаленных элементов. |
call_waitrb_ TIME=0.000000 LINE=45 FILE=tasks.fdv BufferHeader=4dfd48; BufferHandlePtr=906e70; ret_waitrb_ TIME=0.000000 LINE=45 FILE=tasks.fdv
crtbg_ 14.6 Создание группы буферов удаленных элементов
RegularAccessGroupRef crtbg_(long *StaticSignPtr, long *DelBufSignPtr );
|
*StaticSignPtr |
– |
признак создания статической группы буферов. |
|
*DelBufSignPtr |
– |
признак уничтожения всех буферов, входящих в группу, при её уничтожении. |
call_crtbg_ TIME=0.000000 LINE=43 FILE=tasks.fdv StaticSign=0; DelBufSign=1; ret_crtbg_ TIME=0.000000 LINE=43 FILE=tasks.fdv RegularAccessGroupRef=906310;
insrb_ Включение в группу буфера удаленных элементов
long
insrb_(RegularAccessGroupRef
*RegularAccessGroupRefPtr,
long
BufferHeader[]);
|
*RegularAccessGroupRefPtr |
– |
ссылка на группу буферов. |
|
BufferHeader |
– |
заголовок включаемого буфера. |
call_insrb_ TIME=0.000000 LINE=45 FILE=tasks.fdv RegularAccessGroupRefPtr=4e1210; RegularAccessGroupRef=906310; BufferHeader=4dfd48; BufferHeader[0]=906e70 ret_insrb_ TIME=0.000000 LINE=45 FILE=tasks.fdv
loadbg_ Запуск загрузки буферов удаленных элементов заданной группы
long
loadbg_(RegularAccessGroupRef
*RegularAccessGroupRefPtr,
long
*RenewSignPtr);
|
*RegularAccessGroupRefPtr |
– |
ссылка на группу буферов. |
|
*RenewSignPtr |
– |
признак повторной перезагрузки уже загруженной группы буферов. |
call_loadbg_ TIME=0.000000 LINE=43 FILE=tasks.fdv
RegularAccessGroupRefPtr=4e1210; RegularAccessGroupRef=906310; RenewSign=1
FromInitIndexArray[0]=0; FromInitIndexArray[1]=1;
FromLastIndexArray[0]=7; FromLastIndexArray[1]=1;
FromStepArray[0]=1; FromStepArray[1]=1;
ToInitIndexArray[0]=0;
ToLastIndexArray[0]=7;
ToStepArray[0]=1;
ResInitIndexArray[0]=0; ResInitIndexArray[1]=1;
ResLastIndexArray[0]=7; ResLastIndexArray[1]=1;
ResStepArray[0]=1; ResStepArray[1]=1;
ResInitIndexArray[0]=0;
ResLastIndexArray[0]=7;
ResStepArray[0]=1;
FromInitIndexArray[0]=0; FromInitIndexArray[1]=3;
FromLastIndexArray[0]=7; FromLastIndexArray[1]=3;
FromStepArray[0]=1; FromStepArray[1]=1;
ToInitIndexArray[0]=0;
ToLastIndexArray[0]=7;
ToStepArray[0]=1;
ResInitIndexArray[0]=0; ResInitIndexArray[1]=3;
ResLastIndexArray[0]=7; ResLastIndexArray[1]=3;
ResStepArray[0]=1; ResStepArray[1]=1;
ResInitIndexArray[0]=0;
ResLastIndexArray[0]=7;
ResStepArray[0]=1;
ret_loadbg_ TIME=0.010000 LINE=43 FILE=tasks.fdvwaitbg_ Ожидание завершения загрузки буферов удаленных элементов заданной группы
long waitbg_ (RegularAccessGroupRef *RegularAccessGroupRefPtr);
|
*RegularAccessGroupRefPt |
– |
ссылка на группу буферов. |
call_waitbg_ TIME=0.000000 LINE=45 FILE=tasks.fdv RegularAccessGroupRefPtr=4e1210; RegularAccessGroupRef=906310; ret_waitbg_ TIME=0.000000 LINE=45 FILE=tasks.fdv
В.Е.Денисов, В.Н.Ильяков, Н.В.Ковалева, В.А.Крюков.Отладка эффективности DVM-программ. ИПМ им. М.В.Келдыша РАН. Препринт № 74 за 1998 г.