|
|
В ходе
работы над проектом была
решена проблема неадекватной передачи фонетической информации между языками различных языковых групп. Для этого проведён сравнительный фонетический анализ языков восточно-славянской, романо-германской, семитской, китайско-тибетской и тюркской групп языков. В результате анализа выделен универсальный набор фонетических элементов и параметров покрывающий поле указанных групп языков. На основе универсального набора фонетических элементов и параметров разработан фонетический язык-посредник, позволяющий передавать фонетическую информацию между различными языками. Фонетический язык-посредник состоит из фонетической таблицы, содержащей 64 элемента, и правил записи (грамматики) метафонетического представления слов. Каждый элемент таблицы содержит четыре параметра, что позволяет охватить фонетическое разнообразие и осуществить автоматическую транскрипцию между языками восточно-славянской, романо-германской, семитcкой, китайско-тибетской и тюркской групп.
Создана математическая модель машинной транскрипции на основе теоретико-множественного подхода с использованием данного фонетического языка-посредника. Разработанная математическая модель позволила формализовать процесс транскрипции, что существенно упростило процесс создания программных систем транскрипции, в том числе много- и кроссязыковых. На основе модели сформулированы требования к правилам языков, участвующим в транскрипции. Кроме того, формальная модель транскрипции позволяет произвести оценку эффективности транскрипции.
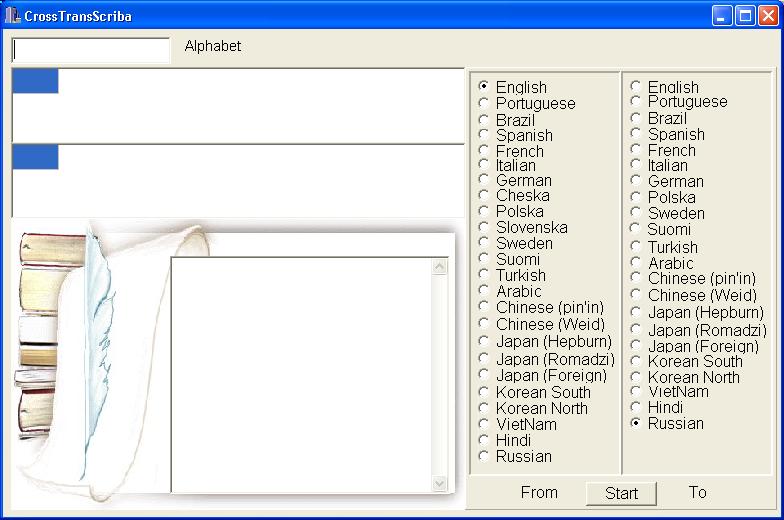
Разработаны правила машинной транскрипции с естественных языков указанных языковых групп на фонетический язык-посредник и с него на английский, немецкий, французский, итальянский, китайский, корейский, японский, турецкий, вьетнамский, испанский, португальский, польский, шведский, чешский, словенский, русский, хинди, финский и арабский языки.
Разработаны электронные лингвистические базы правил машинной транскрипции, слогоделения, расстановки ударений, как для национальных алфавитов, так и для записи латиницей без диакритических знаков для указанных языков.
Разработан прототип программы машинной кросстранскрипции способной выполнять транскрипцию между языками восточно-славянской, романо-германской, семитcкой, китайско-тибетской и тюркской группам языков.
Экспериментально исследована машинная кросстранскрипция между английским, немецким, французским, итальянским, китайским, корейским, японским, турецким, вьетнамским, испанским, португальским, польским, шведским, чешским, словенским, русским, хинди, финским и арабским языками.
По каждому языку создана тестовая база имен собственных. Разработана методика регрессионного тестирования, позволяющая выделить оптимальный набор правил кросстранскрипции.
Впервые математически обоснована и впервые экспериментально подтверждена возможность автоматической кросстранскрипции на основе фонетического языка-посредника между языками различных языковых групп.
Степень новизны полученных результатов:
Все результаты получены впервые. Математическая модель машинной транскрипции на основе фонетического языка-посредника и единой фонетической таблицы разработана впервые. Имеющиеся аналоги исходят из непосредственного сопоставления правил транскрипции одного языка правилам другого языка. Это приводит к необходимости создания правил транскрипции каждого языка с каждым, то есть n(n-1) транскрипционных таблиц. Единая фонетическая таблица существенно отличается от международной фонетической системы, так как изначально ориентирована на использование в алгоритмах машинной транскрипции. Её использование позволяет уменьшить число таблиц транскрипции до 2n.
Впервые разработана методика позволяющая путем машинного анализа лингвистической информации выделить из большой группы языков универсальную группу фонетических элементов пригодную для организации автоматической передачи фонетической информации между различными языками.
Впервые разработан прототип программы машинной транскрипции на основе фонетического языка посредника.
Впервые автоматическая транскрипция осуществляется с учетом правил ударения, слогоделения, применившихся ранее правил транскрипции, положения в слове транскрибируемого сочетания букв, закрытости или открытости слогов, последующих гласных или согласных, учета потери лингвистической информации, при записи латиницей без диакритических знаков.
Сопоставление полученных результатов с мировым уровнем:
Полученная фонетическая таблица и основанный на ней язык-посредник объединяет в себе фонемы различных языков, что выгодно отличает ее от существующих национальных таблиц. Создание математической модели машинной транскрипции, основанной на методах теории множеств, до сих пор нигде в мире не производилось. Указанные языки являются основными и охватывают 4 миллиарда человек на планете.
Количество научных работ, опубликованных в ходе выполнения проекта: 10
|